
The Route That Outsourced Judgment to the Tool
How an AI recommendation became a decision without anyone deciding (Route Rebuilder | Episode 5)

👋 Welcome to this week’s edition of Empathy Engine. Every Wednesday, I publish a new article for paid subscribers first, then unlock the full piece for everyone late Thursday morning. Each week, I turn product leadership friction into practical tools, sharper language, and more defensible decisions.
Research Binder: the receipts (citations + source notes) are compiled in a PDF at the bottom of this post.

If You’re Skimming
An AI tool can recommend, suggest a fix, score its own confidence, even auto-merge. A recommendation is still not a decision.
The broken route here: human-in-the-loop on paper becomes human-near-the-loop in practice, then absent under pressure.
The fix is not less AI. It is explicit routing: a named judgment owner, real authority, an escalation trigger, and an audit trail.
Run the Five-AI-Decision Field Test at the bottom to inspect your own workflows before the next high-confidence suggestion ships.
Who Owns the Judgment When the Tool Says Yes?
Before this article had a clean thesis, it gave me a live demonstration of the problem. I had the first draft reviewed by several AI systems, and one came back with exactly the feedback a tired writer wants to see: polished, confident, encouraging, and close enough to my own language that it felt safe. It told me the piece was strong. It said the series callbacks were present and praised the recurring structure. The review looked clean. The signal looked strong. The grade was flattering enough to make my inner editor briefly consider taking the afternoon off and calling that discernment.
Then I checked it against the actual draft. Some of the feedback was genuinely useful. But part of the review praised structural elements that were not there. It had turned plausibility into confidence, and confidence into something that almost felt like approval. The failure would not have been the AI making a wrong call. The failure would have been me letting a confident recommendation become editorial judgment without owning the yes myself. That is the route failure this piece is about.
I caught it only because I went and checked. The same trap waits in an engineer’s review queue, where the confident recommendation is a code change, the deadline is real, and the merge button does not care whether anyone actually decided.
Episode 1 Parts A and B:


This series has been tracing one failure through different rooms. In Episode 1, a warning died in a busy channel because receiving is not routing. In Episode 2, a handoff became a gap because a closed ticket is not a completed handoff. In Episode 3, a review gate lived on the diagram but stopped operating in the work. In Episode 4, a green dashboard counted closure while rework hid in the shadow. Episode 5 follows the same pattern one layer deeper, into the moment an AI recommendation becomes the decision because no one explicitly owned the judgment point.
Episdoe 2:

Episode 3:

Episode 4:

This is not an anti-AI argument. AI-assisted tools can help teams move faster, spot patterns, and reduce routine friction. The problem begins when speed quietly absorbs judgment. A dangerous workflow is not necessarily the one with no human anywhere near it. Sometimes it has a human nearby, a confidence score on the screen, a review step in the policy, and a merge that still behaves as if the decision was already made. The first route to inspect is not the code path. It is the decision path.
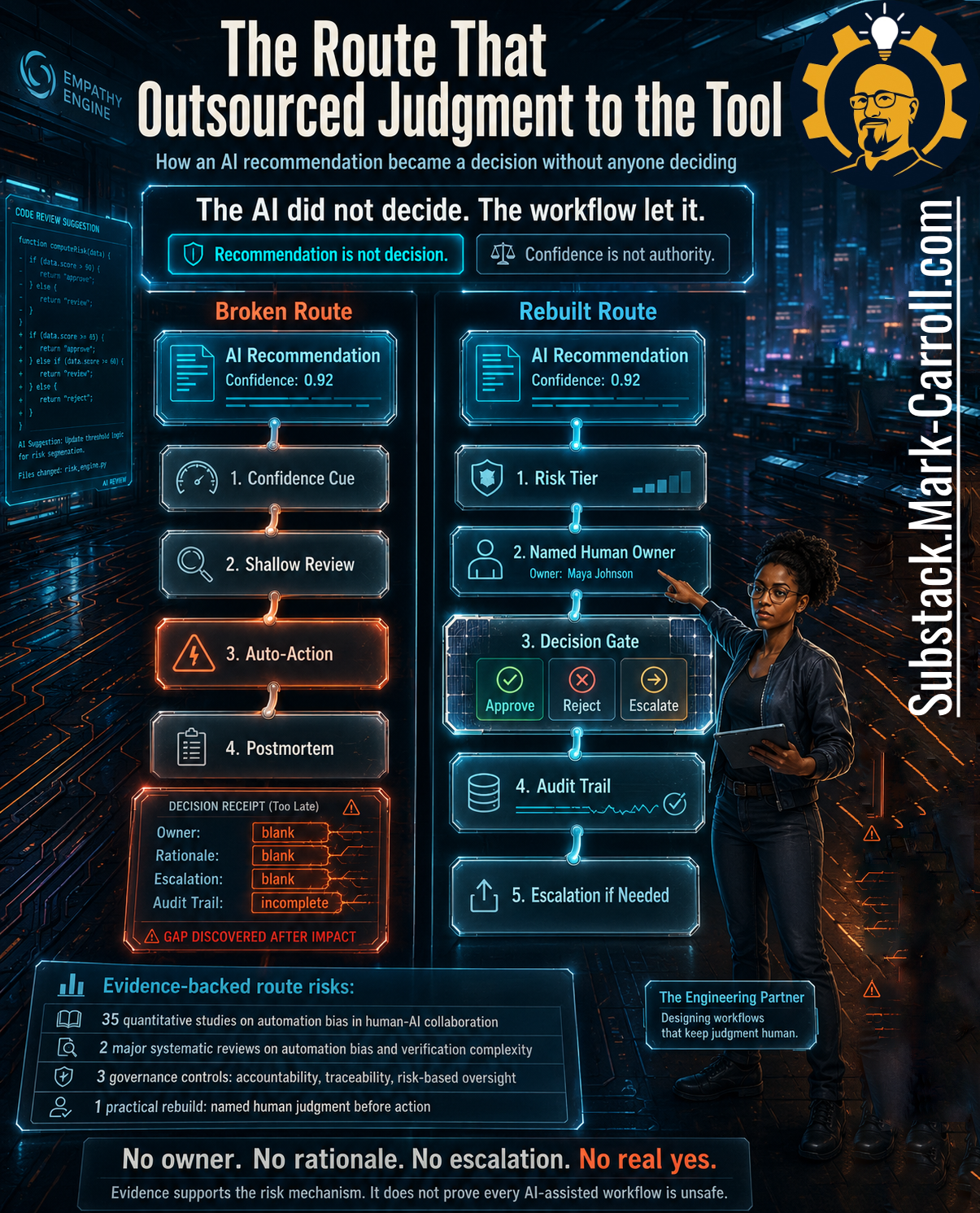
When the Recommendation Became the Route
When did the recommendation become a decision?
That is the question most teams do not ask early enough. They ask whether the tool was accurate, whether the test suite passed, whether the code looked clean. The deeper question is whether the recommendation passed through a real decision point before action happened. A recommendation is an input. A decision is an owned commitment.
Picture a composite team, drawn from patterns I have seen across many organizations rather than any single client. Their AI code review tool flags an issue, suggests a fix, attaches a confidence score, and routes the change into the review path. A reviewer recognizes the shape of it and approves quickly. At first nothing seems broken. The process is faster, the pull request looks cleaner, the queue moves. Then a vulnerability surfaces, or a logic assumption fails under load, and the postmortem can reconstruct the recommendation, the score, the timestamp, and the merge. What it cannot reconstruct is the human judgment that owned the yes.
A decision needs an accountable route: someone who could approve, someone who could reject, someone who could escalate, and the evidence that belonged in that choice. Without that route, the system has motion but not ownership. The practical question is not whether AI belongs in code review. It is whether the workflow still knows when an AI recommendation is only a recommendation.
The Score That Sounded Like a Yes
What made the score feel like authority?
In Episode 1, we named the Ack Trap: acknowledgment creating the appearance of control. At a confidence score, the same trap runs at machine speed. A high number feels like proof. It starts to sound like “already checked,” especially when the reviewer is busy, the change looks clean, and the tool has been useful before.
Research on automation bias gives this failure mode a name. One review of thirty-five quantitative studies on human-AI collaboration, together with two major systematic reviews of automation bias and verification complexity, points to the same pattern: people can over-rely on automated recommendations, particularly when the system appears reliable, when verification is complex, and when workload is high. Those three amplifiers, workload, task complexity, and perceived reliability, describe a normal code review almost exactly. That does not mean humans always over-trust AI. Trust can be too high, too low, or badly calibrated. Code review is simply a near-perfect environment for the calibration to drift.
I have had green signals quiet my better judgment, and not only from AI. Sometimes the signal was a test suite. Sometimes it was a work item moving across a board in Azure DevOps with just enough completion language to make everyone feel better than the evidence deserved. The part of me that hesitated usually noticed something small: a teammate who answered too quickly, a dependency mentioned once and then gone from the conversation, a “done” column that had become more important than the conditions that made the work done. The signal won because the signal was easier to defend than the instinct. Nobody wants to be the person slowing the room because a status update feels off. A green check has institutional charisma. It looks objective, calm, and finished, which is a very convenient costume for unfinished judgment. The problem was not that I made the wrong call. It was that I let the visible signal stand in for the uncomfortable question: do we actually know enough to say yes?
The trap is not the score itself. The trap is the workflow treating the score as if it carries authority. A confidence score can prioritize attention and suggest where to inspect. It cannot own the yes. Confidence is not authority, and a high score should focus judgment, not replace it.

The Pull Request Looked Fine
What can polished code hide?
The risky AI suggestion may not look sloppy. That is the uncomfortable part. It may be clean, idiomatic, neatly formatted, and surrounded by green checks. When teams imagine bad AI code, they imagine something obvious: broken syntax, strange names, a function that looks like it wandered out of a forum answer from 2008 wearing someone else’s hoodie. Real risk is quieter.
Studies of AI-generated code make the boundary clear. One multi-language study of two hundred coding tasks across four languages and five models found nontrivial security and quality issues that vary by language, model, and task. Secure-generation research reduced observed vulnerabilities by more than sixty-five percent in tested scenarios, which is encouraging and also a reminder that the baseline risk was real. None of this proves AI code is broadly worse than human code. The more precise claim is that AI-generated code can carry a distinct, nontrivial risk profile, and some of that risk is visible only to a reviewer who understands the system context.
A pull request can pass surface checks and still miss the point. Tests confirm the behavior the suite already imagined. Linters confirm the code looks orderly. Static checks catch some categories and miss others. Clean style is not system understanding. The fluency is the trap: code in the house style, with a reasonable-sounding explanation, can read as comprehension when it is only polish. Three things often hide behind that polish: a security gap, a logic assumption, and an outdated pattern. The fix is not paranoia. It is context-aware review, routed by risk, so that a payment path or an authentication change never travels the same road as a typo fix.

