
The Demo Found the Gap
How a handoff became a gap when nobody named a receiver (Route Rebuilder | Episode 2)


The Demo Found the Gap
The demo is going well, which is the dangerous part. Dana has run this customer demo in her head a dozen times, and the board has been green all sprint. The feature shipped on time. The client is leaning in, nodding, asking the kind of questions you only ask when you are already imagining the rollout.
Then Dana clicks through to the new data feed. The screen hangs on a spinner. The spinner turns over once, twice, and resolves into a 500 error, live, in the one room where it absolutely cannot. Someone laughs the wrong kind of laugh. The client’s polite smile tightens into a polite question: “Is that something on your end?”
In Part B, The Rebuilt Route, the core distinction was simple: receiving is not routing. This demo exposes the next failure in that same family. Three external dependencies fed the feature. Each had its own ticket, assignee, and due date. Six weeks ago, all three were marked done. Every record says this work is finished, owned, and shipped.

So why is it failing now, in front of the customer, on the one path everyone swore was complete?
👋 Welcome to this week’s edition of Empathy Engine. Every Wednesday, I publish a new article for paid subscribers first, then unlock the full piece for everyone late Thursday morning. Each week, I turn product leadership friction into practical tools, sharper language, and more defensible decisions.
Research Binder: the receipts (citations + source notes) are compiled in a PDF at the bottom of this post.
If You’re Skimming
A closed ticket is not a completed handoff.
Cross-team work fails most often where ownership is assumed, not accepted.
The fix is not another meeting. It is naming who catches the work, and confirming they caught it.
Run the Five-Handoff Field Test at the bottom to find where your own routes leave ownership optional.

The Handoff That Wasn’t
The team did not fail because nobody owned the work. The team failed because nobody owned the transfer of the work. That distinction is small enough to miss in a standup and expensive enough to surface in a demo.
In Episode 1, we said it plainly: receiving is not routing. A warning can land in a channel and never reach an owner. Here the same failure repeats one boundary over, at the handoff between teams. The sender marks the work done and believes it moved. The receiving team gets a notification, assumes it is backlog grooming, and lets it sit. No one is wrong, and no one caught the baton.
Dana, Sam, and Priya are composites (not a disguised client or one remembered demo). I use them because the pattern is real even when no single incident should carry the whole argument. I have seen versions of this in planning rooms, retros, tool rollouts, and dependency reviews. The names change, the tools change, the industry changes; the move does not. The work becomes visible, the room relaxes, and no one confirms that ownership landed.
Here is the confession. I have seen a handoff clearly and still let it drop (not because I was careless, and not because the people around me were, but because the work looked visible enough to feel safe). It was the professional version of setting the baton down behind me without glancing back to see whether the next runner had a hand out. I told myself someone closer to the work had it. Later, when the dependency resurfaced, I understood what the route had actually produced: awareness without acceptance.
Closed Ticket, Open Handoff

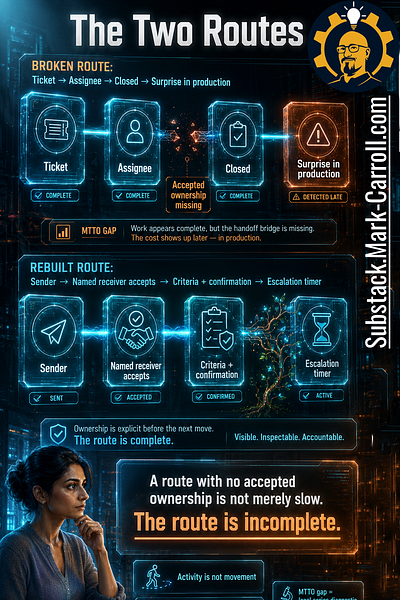
There are two routes hiding inside every dependency, and we usually only watch one of them. The first is the route the tool records: ticket, assignee, status, closed. It has a clean beginning and a clean end, which is exactly why it looks finished.
The second is the route the work actually needed: sender, named receiver, accepted criteria, a confirmation that someone caught it. Those are not the same route, and the gap between them is where six weeks of silence live.
Picture a relay. The runner who finishes a leg does not get to decide the baton was passed. The pass only happens when the next runner’s hand closes around it. What we built instead is a track where the first runner sets the baton down, the clock keeps running, and everyone stands around admiring the relay dashboard. The board is green because the baton was placed. Nobody confirmed it was taken.

A closed ticket is not a completed handoff. A closed ticket means a record reached its endpoint. A completed handoff means someone caught the work (understood what arrived, knew what good looked like, and knew when to escalate). The difference is where ownership either lands or quietly becomes optional.
This is the line worth keeping: closed ticket, open handoff. The dashboard in Dana’s demo was not lying; it was answering the wrong question. It could tell her the tickets were closed. It could not tell her whether anyone had accepted what came next.
That is one of the illusions this article is built to diagnose. Not the only failure a team can have, but a specific, common, and fixable one: work that everyone can see and no one has caught.
The Ack Trap at Scale
Once a handoff moves into a shared channel, a quieter failure shows up. Acknowledgment starts to feel like movement.

It looks like this. Sam posts in the platform channel: “Hey team, auth dependency is ready for integration. Shout if you need anything.” A thumbs-up appears. Someone adds “nice, thanks!” The thread goes calm, the sender feels heard, and the group feels aligned. What none of that produced is a person who has said, out loud, “I’ve got it.”
An emoji is a read receipt. “Looks good” is a courtesy. Neither one is acceptance, and the difference is invisible right up until the demo. A useful lens here is diffusion of responsibility (when a message goes to a group and no one is named, it gets easier for each person to assume someone else will pick it up). I am borrowing that idea as a metaphor, not claiming your Slack channel behaves like a laboratory. But the shape is familiar enough to respect: the more people who can see a thing, the less certain it is that any one of them owns it.
There is a human reason this happens, and it is not laziness. Saying “I accept this” means signing up for the next move. Saying “this isn’t ready, I can’t take it yet” means friction with a colleague. A thumbs-up costs nothing and buys a day of quiet. In a hurry, the cheap signal often wins. Everyone saw it. That was the problem.
The Optional Receiver
I have a name for this pattern in the series: the Optional Receiver. It is a handoff where no specific person or team has clearly accepted the next move, so the route treats acceptance as something that will simply happen on its own.
Watch the chain of assumptions. The sender assumes the group saw it. The group assumes someone will clarify. The manager assumes the tool will surface anything stuck. The customer assumes the product will work. Written out, the chain looks absurd. Lived inside a busy sprint, it feels completely normal.
If you have ever marked something done and then stayed online a little longer because you were not entirely sure it had landed with anyone (you have felt this gap from the inside). That low background hum is the sound of work that is visible and unowned. It does not need a villain to stall there. It only needs a route that never forced anyone to say yes, no, or not yet. That is why the next move cannot be blame. It has to be route tracing.
Trace the Route, Not the Blame
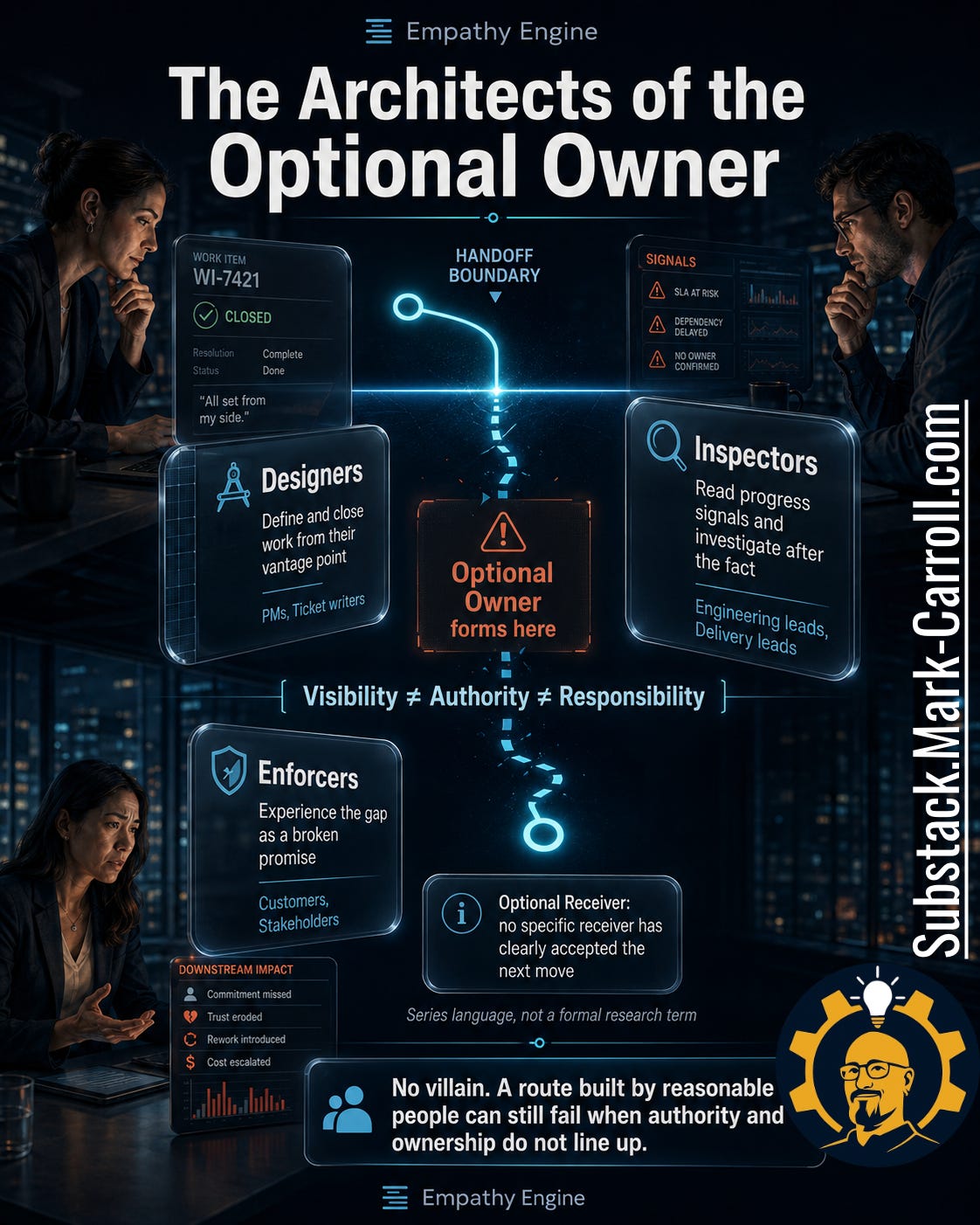
This gap is almost never built by careless people. It is built by reasonable people whose vantage points do not line up. The designers of the route (the PMs who write and close the tickets) see work leave their board and read that as complete. The inspectors (the leads watching velocity and running the retro afterward) see healthy movement. The enforcers (the customers and account teams) feel the gap last, as a broken promise.
You can watch all three truths collide in a postmortem. Someone shares their screen and scrolls back through the ticket history. “It was assigned six weeks ago,” the PM says, and the history agrees. “I got a notification,” the platform engineer says, “and I assumed it was grooming.” The history agrees with that too. The room goes quiet, because everyone in it acted reasonably and the work still fell through.
The instinct I have earned in that quiet is to listen for two words: I thought. “I thought they had it.” “I thought that meant it was done.” “I thought the other team was tracking it.” When those sentences start arriving, I stop the conversation and ask what the route actually confirmed. “I thought” is often the sound a missing handoff makes after the fact.
That is why blame is the lazy diagnosis. The useful question after a handoff fails is not “who dropped this?” It is “where did the route let this drop?” When the person who can see the warning is not the person with the authority to move it, the route is already fragile (and no amount of trying harder closes that gap). A blameless review is not softer than blame. It is stricter, because blame stops at the nearest name and the route keeps failing the next time.
The Local Cost of an Unowned Handoff
The cost of an unowned handoff is real, but the honest number is local. There are broad industry estimates for the cost of poor software quality (useful for sizing the problem space, but they are industry-wide figures, not handoff-specific, and borrowing one to describe your team would be a guess wearing a suit).
The honest accounting lives in your own work, and it comes in three shapes. Bystander Burn is the time several people spend seeing, monitoring, and half-investigating a thing nobody has accepted. Investigation Tax is the duplicated effort when the gap finally surfaces and someone has to reconstruct what happened. Compounding Rework is the cleanup when downstream work was built on a foundation that was never confirmed.
You do not need a number to feel it. I have watched the cost of an unowned handoff accumulate without a single dramatic failure. First the clarification thread. Then the duplicate investigation. Then the meeting where everyone tried to reconstruct what should have happened when the work changed hands. By the time the team understood the gap, the original task was no longer the only work (the cleanup had become its own dependency). Picture three people each losing an afternoon to a dependency no one accepted: that is a workday gone before the real fix even starts. Your numbers will differ; the pattern will not. The point is to stop pretending the gap was free.
The Ownership Assignment Checklist
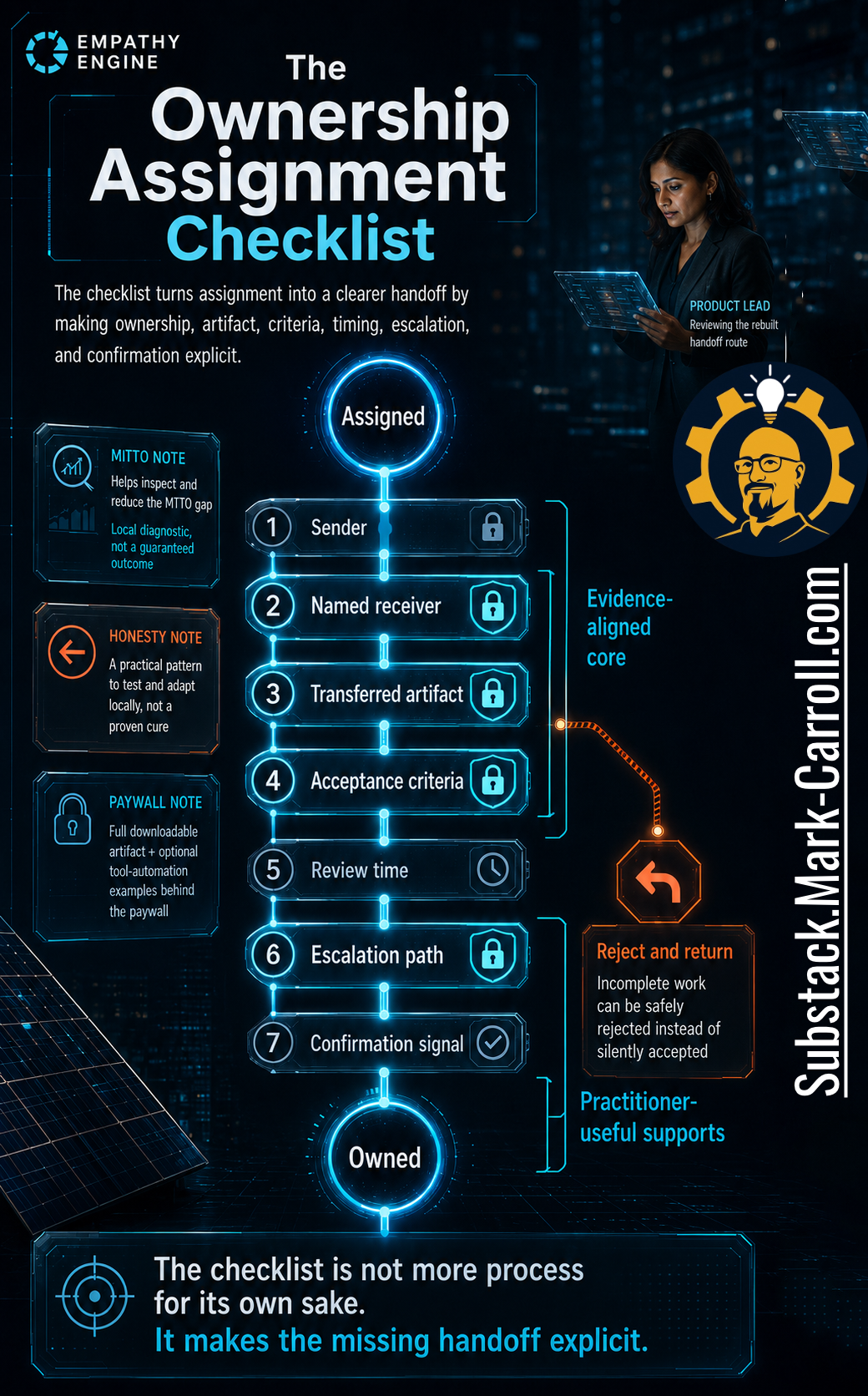
The repair does not start with a bigger meeting. It starts with a smaller, clearer handoff (one that makes acceptance visible before the work moves on).

Rewind to the Tuesday Sam marked his dependency done, and watch the same moment go differently. Instead of “Backend dependency complete. Marking done,” Sam writes: “Ready for mobile integration. Receiver: Priya. Artifact: API contract v3 and test payloads. Acceptance criteria: mobile confirms response format and error handling by Thursday 2pm. Escalation: if not confirmed by then, route to dependency review. Confirmation: comment ‘accepted for integration’ on this ticket.” Priya reads it, finds the error-handling spec thin, and replies “returning (need the 4xx cases before I can accept).” That is not a failed handoff. That is the first handoff in this whole story that actually worked.
The difference is not paperwork. It is that someone is now the catcher (the named person who has to say I’ve got it or not yet, and either answer moves the route forward). Before you close any cross-team dependency, you can run a three-minute pass over the checklist’s core questions: who receives this, what exactly are they receiving, what do they now own, what proves they accepted it, and when do we escalate if they do not? If you cannot answer those, the ticket may be closed, but the route is still open.
What I have seen work are pieces of this, not a perfect system (a named-owner rule here, a blocker-escalation policy there, a readiness check that stopped one team from pulling work forward before the receiver had accepted it). The pieces worked when they changed behavior in the room, not when they looked impressive in a process document. They failed when they became invisible, optional, or socially unsafe to use. That is why I trust lightweight mechanisms, but only when each handoff comes out a little clearer than the last.
A word on what this is and is not, so the rest of the piece can stay confident. The checklist does not guarantee success; it gives a team a place to ask the questions that prevent silent failure. It does not create the trust that lets someone say not yet. It gives them shared, neutral language for using the trust they already have (“we’re missing acceptance criteria,” not “you did this wrong”). And it is a pattern to test and adapt to your own work, not a certified standard or a cure. Right-size it: heavier where the handoff crosses teams, customers, or release boundaries; barely there for routine work.
The Five-Handoff Field Test
The Five-Handoff Field Test. This week, pick the next five cross-team handoffs and, for each one, check:
Was a receiver named?
Did that receiver explicitly accept?
Were the acceptance criteria clear?
Was there an escalation path?
Was there a confirmation signal?
Circle the handoff where no one was the catcher. That is your first repair. The review question that travels with it is short enough to say in any standup:

Now run Dana’s demo again, in the version where Sam named Priya and Priya accepted. The new data feed loads. The integration holds, because the team that owned it knew it was theirs three weeks before anyone pointed a projector at it. The difference between the demo that failed and the demo that held was not talent, effort, or a better tool. It was a route that made someone catch the baton.
The Rebuild
Subscribers receive the Ownership Assignment Checklist for this episode. It turns a vague handoff into a lightweight, seven-field agreement (sender, named receiver, transferred artifact, acceptance criteria, review time, escalation path, and confirmation signal) that you can drop onto any cross-team ticket in under three minutes.
It also includes the reject-and-return path so receivers can push back on incomplete work safely, a local MTTO diagnostic for measuring your own time-to-ownership, and optional tool-automation examples for making incomplete handoffs harder to miss.
A note on that diagnostic: MTTO is a local lens in this series, not an industry benchmark. Use it to inspect your own ownership gaps, not to pretend your context matches anyone else’s.
The Route Was Missing
The team in the opening did not lack effort, tools, or assigned work. The ticket had a name. The board had a status. The demo had a date. What it lacked was a moment where someone caught the work and said so.
A closed ticket can end a task. Only accepted ownership completes the route. That is the whole difference between work that looks finished and work that survives the next handoff, and it is the difference between Dana’s first demo and her second.

This is also the larger argument behind my upcoming book, Collaborate Better. Better collaboration is not softer language or more cheerful meetings. It is the discipline of making work, ownership, trust, and decisions visible enough for people to act on them together. You can learn more at CollaborateBetter.us.
Next in Route Rebuilder: Part 3, The Route That Trained Override Behavior (how a review gate became the thing everyone learned to skip).
Next:

P.S. What is the last handoff you saw that looked closed but was not complete? Reply and tell me about the moment the work looked assigned but the route still failed. I read every one.
Regards,
Mark 👋

Previous:

More Content to Discover:



The most dangerous handoff is not the one nobody sees.
It is the one everyone sees, because visibility makes the room relax before ownership has actually landed.
A closed ticket can end a task, but only accepted ownership completes the route. This piece is about the quiet gap between “someone saw it” and “someone caught it,” plus the practical checklist teams can use before the next baton hits the floor.
♻️ Restack if your team has ever discovered too late that “done” only meant the ticket moved.