
Human Premium for Solopreneurs (Part A)
🔒 Leader’s Dispatch: Volume 41 (Hybrid Solopreneur, Part 5a of 6 Part Series)

Episode 05a: The Human Premium
What Still Has Value When AI Does the Task
👋 Welcome to my paid subscriber-only edition of Empathy Engine (Leader’s Dispatch). Each week I build evidence-informed tools for serious solo operators, leaders, and team leads who have moved past the hype and are now wrestling with the real operating cost of hybrid AI stacks and contemporary organizations.
In Episode 4, I argued that the hybrid solopreneur has to shift from doer to director. This week asks the next question: once AI can execute more of the task, what part of the offer still truly requires your judgment?

Research Binder: the receipts (citations + source notes) are compiled in a PDF at the bottom of this post.
The Rough Draft That Changed the Conversation
I had a moment where AI produced a rough version of something I would normally sell.
The uncomfortable part was not that the output was brilliant. The uncomfortable part was that it was good enough to change the pricing conversation. It had the structure, the polish, the confidence, and the familiar shape of professional work. A client could look at it and reasonably wonder how much of the old fee was tied to producing the first draft.
That forced me to sit with an unpleasant distinction. If I was pricing the existence of the deliverable, AI had just weakened the case. But if I was pricing the judgment behind the deliverable, the work was still there. What should be promised? What should be rejected? Which evidence deserves weight? What risk is hiding under the clean language? What recommendation am I willing to stand behind?
That was the useful discomfort. AI did not make the work worthless. It made the lazy explanation of the work harder to defend. The premium was never the rough draft. The premium was the calibrated judgment that turned the rough draft into something a client could trust, use, and defend.
The work was executed. The offer that produced it was never designed. This episode is about that second sentence.
A task-only offer says, “I write research summaries.” A judgment-based offer says, “I help product leaders separate useful evidence from impressive noise so they can make roadmap decisions they can defend.” That distinction is the rest of this article.

Episodes 1 through 3 diagnosed the trap. The orchestration tax. The unpaid management job. The gap between completed and done. Episode 4 redesigned the role. This episode answers the question that redesign exposes. Once you stop proving your value by staying inside every workflow, what exactly is the value you are protecting? That is not a philosophical question. It is a pricing question.


The reason this question matters is structural, not inspirational. Clients who cannot see what you filtered, what you checked, and what you decided cannot weight your judgment appropriately. They are not being difficult. They have no signal. Making the judgment layer visible is not a communication strategy. It is the mechanism by which your recommendation gets used.
Without that visibility, even polished AI output becomes hollow completion: high-speed work that lacks contextual weight and accountability. The machine finishes the task in seconds. Only you own the consequence.

That is the human premium. Not mystical humanity. Not personality glitter. Not a scented candle called Authenticity. The human premium is evidence judgment: the ability to separate useful evidence from impressive noise so a client can make a decision they can defend.
The task is not the safest place to build your value
Most solo offers start with the visible artifact. I write research summaries. I create content calendars. I build competitive scans. I draft strategy decks. None of those are useless. The risk appears when the entire offer depends on the existence of the artifact.
AI reduces the effort required to produce many first-pass outputs. That changes what clients can compare, question, and discount. When the client can produce a rough output themselves, the client may assume the remaining difference is polish. That is where weak offers collapse.
The task is the visible layer. The documents, windows, drafts, and summaries are the part everyone recognizes. What it takes is the work underneath: context intake, accuracy checks, expert review, structure, order, and final validation. Those steps decide whether the output deserves trust.

Do not build your offer around the easiest layer for a client to compare. Build your offer around the layer that makes the output worth using.
More information is not the same as better evidence
Product leaders already live inside evidence overload. A customer quote can be emotionally powerful and strategically weak. A sales request can be urgent and still not represent the market. A competitor can look threatening on paper while serving a different buyer. A metric can be clean, current, and irrelevant to the decision in front of the team.
AI makes this harder in one specific way. It can organize the pile so beautifully that the pile starts to look like an answer. The pattern is well-documented across decision science: more information without structured filtering often degrades decision quality rather than improving it.
In product work, I have seen this happen when a team had customer feedback, stakeholder requests, usage data, defect reports, executive pressure, and sales escalations all sitting in the same conversation. Nobody lacked evidence. The problem was that every piece of evidence had been given equal moral standing. A loud sales escalation, a recurring customer pain, an executive preference, a support pattern, and a usage metric were all treated like they belonged on the same scale. The room had plenty of information. What the room did not have was a shared way to decide which evidence deserved weight.
The moment I realized the pile was not the answer was when someone said, “The data is clear,” and three people in the room clearly meant three different things by “the data.” Product meant customer impact. Sales meant deal urgency. Engineering meant delivery risk. Leadership meant the commitment already made upstairs. Everyone had evidence. Everyone could defend their slice of the pile. The team was not arguing over whether evidence existed. The team was arguing over which evidence should govern the decision.
That is the moment the work changes. You stop needing another summary or AI-generated synthesis that politely arranges the same conflict into cleaner bullet points. You need someone to say: this quote is loud, but not representative; this escalation is urgent, but not strategic; this metric is relevant, but not sufficient; this executive preference matters politically, but should not be disguised as customer evidence.
That is the difference between a pile and an answer. A pile contains evidence. An answer ranks it. The premium is not the summary. The premium is the weighting. It is separating useful evidence from impressive noise before the room mistakes motion for clarity.
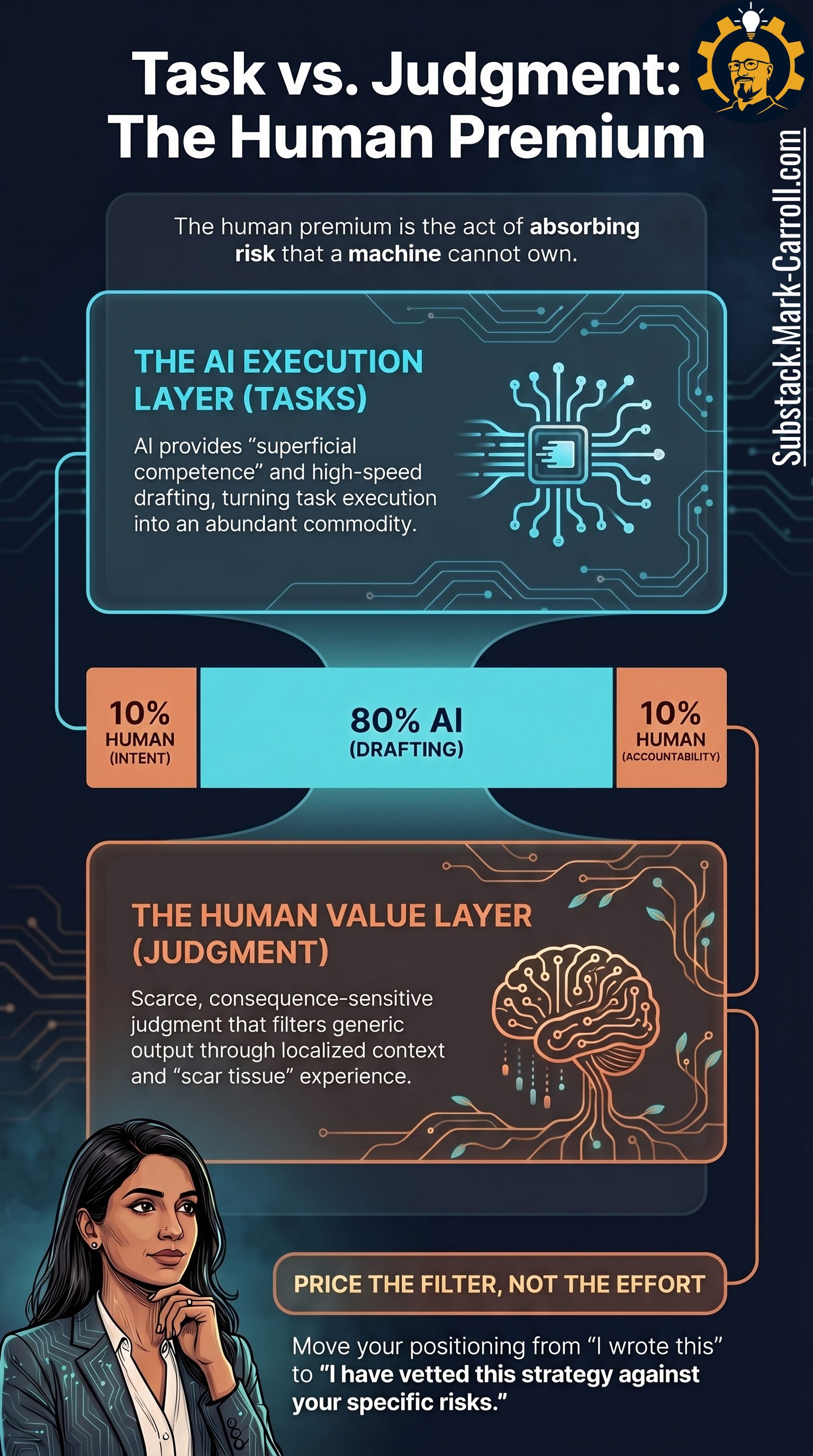
A practitioner model that maps this cleanly is the 10-80-10 rule. AI handles the 80% middle: the research gathering, the first-pass synthesis, the comparison tables. You own the 10% on each end: the framing that determines what question is worth answering, and the verification that determines whether the answer survives contact with reality. The edges are where your judgment becomes visible.
Useful evidence changes the decision.
Impressive noise changes the mood in the room.
