
Part B: The Rebuilt Route
The local cost, postmortem question, and decision aid (Route Rebuilder | Episode 1b)

Part B: The Rebuilt Route
👋 Welcome to this week’s edition of Empathy Engine. Every Wednesday, I publish a new article for paid subscribers first, then unlock the full piece for everyone late Thursday morning. Each week, I turn product leadership friction into practical tools, sharper language, and more defensible decisions.

Research Binder: the receipts (citations + source notes) are compiled in a PDF at the bottom of this post.
In Part A, a visible warning sat in an incident channel for fourteen days while the room assumed someone else owned it. We named that failure an Orphaned Alert and showed how acknowledgment fakes ownership, how reasonable people build the broken route, and why the failure stays invisible from above.

Now: what does that missing route actually cost, and what does the rebuild look like?
The cost of a broken route is easier to see when you trace two paths from the same warning.
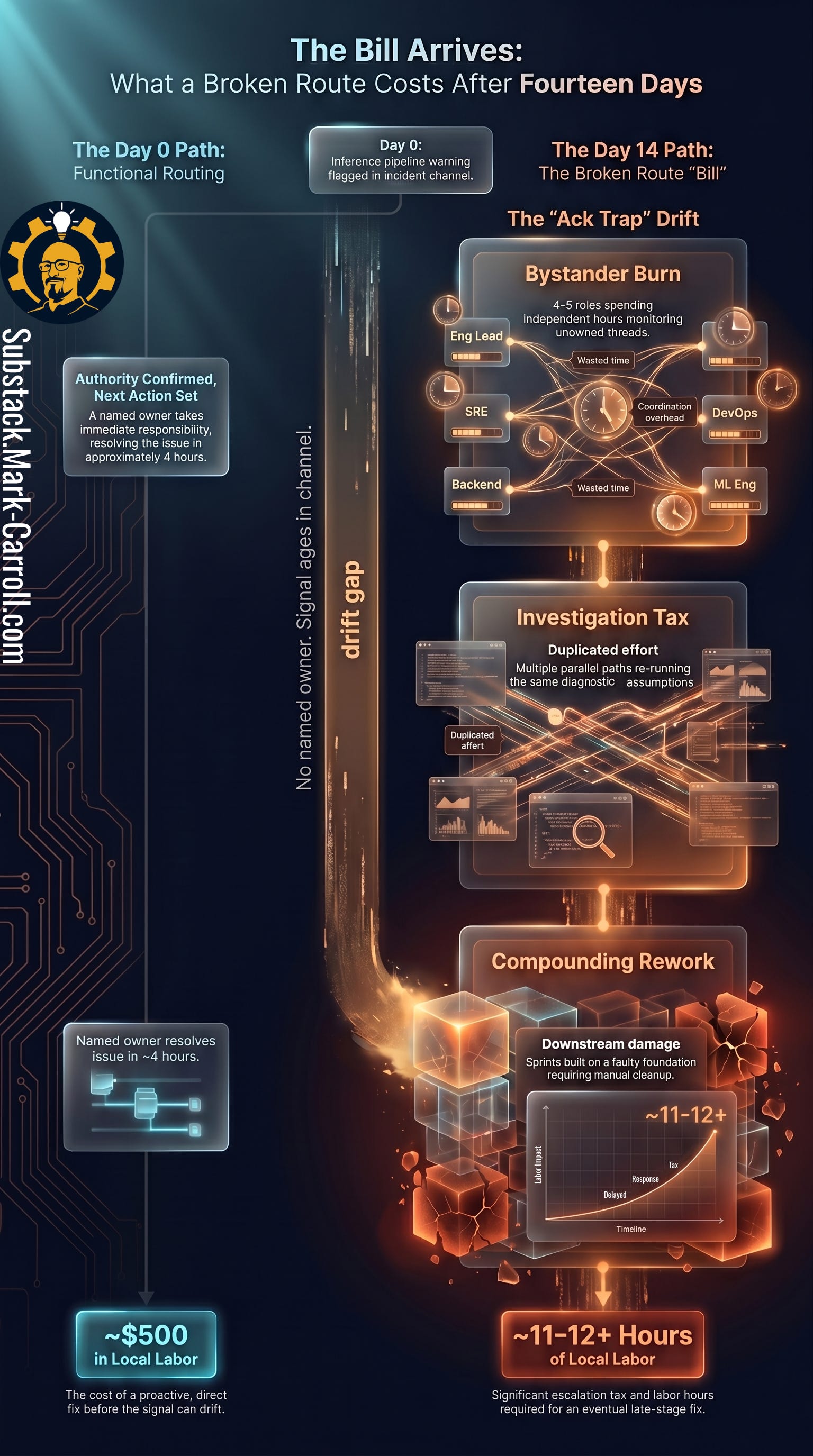
The local cost of a broken route
The cost language in this article is local and illustrative. I am describing estimate categories a team can adapt using its own labor rates, timelines, and remediation data. The point is not that every team pays the same amount. The point is that the labor cost of a broken route usually hides inside normal work until someone traces it.
Three local cost categories tend to surface when you trace a broken route backward.
Bystander Burn is the coordination time multiple people spend seeing, monitoring, or briefly investigating an unowned warning.
Investigation Tax is the duplicated effort that appears when the first investigation does not become a documented handoff.
Compounding Rework is the extra cleanup and remediation that accumulates when a known problem sits unresolved while downstream work continues building on top of it.
I have traced this kind of cost through an Azure DevOps board. A work item was marked blocked, comments were added, and the assignee was visible, so the board looked like it had captured the risk. But the person assigned to the work did not own the decision that would unblock it. Over the next week, the item appeared in standup, backlog refinement, a review conversation, and a stakeholder update. Each time it generated questions nobody could close.
The conservative cost: two developers spending roughly three hours each checking the dependency, a delivery lead spending two hours chasing status, a product owner adjusting expectations, and a lead reconstructing who could actually make the decision. Roughly eleven to twelve hours before counting the eventual fix.
Multiply those hours by your team’s loaded rate and the math becomes local, specific, and hard to ignore. A $500 Day 0 fix quietly became a multi-week remediation because the signal had a channel but not a route.
The Day 0 fix would have been boring: name the decision owner, confirm the authority, and set a twenty-four-hour escalation rule. Boring would have been cheaper.
That is why the math should stay local. A team does not need to claim that every minute of delay costs some theatrical number borrowed from a vendor deck. The team only needs to ask what the delay cost here, in this workflow, with these people, this cleanup, and this missed handoff. The route did not save time. It moved the cost to more calendars.

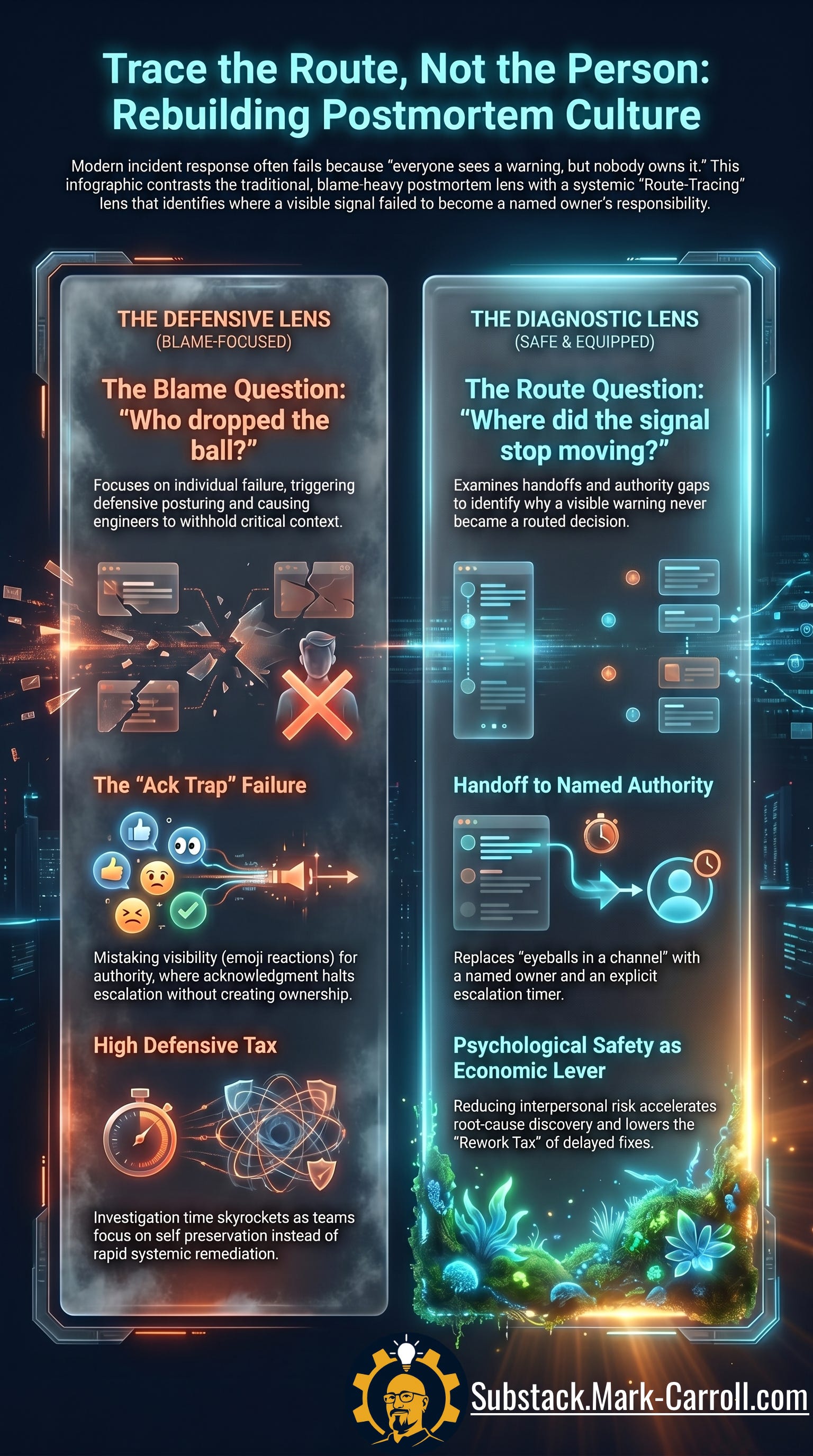
Trace the route, not the person
Ownership language turns dangerous when handled badly. “When did this become someone’s job?” is a useful question when the team is tracing the route. The same question becomes politically unsafe when the team is hunting for a person to blame.
A blameless review does not mean no one is accountable. It means the review inspects system conditions, handoffs, and authority gaps before inferring personal failure. Accountability still matters. But accountability works better when people know what they owned, what authority they had, and where the next move should have gone. The safest postmortem questions are route questions: where did the signal first become visible, what happened between visibility and explicit ownership, and what timer or escalation rule should have moved the signal when ownership remained unclear?
I have facilitated retrospectives that handled the same kind of failure in completely different ways. In the weaker version, the room decides the problem was “communication.” Nobody says “we are blaming someone,” but the questions start orbiting the person closest to the miss. The retro ends with an action item like “communicate sooner,” and everyone nods because nobody wants to argue with a virtue. The weeks afterward reveal the real effect: people become more careful, not more transparent. They bring screenshots, soften risks, and turn updates into little legal exhibits for the defense. That is not learning. That is workplace theater with better bullet points.
The better reviews feel different in the first five minutes. They still ask hard questions, but the questions follow the route: where did the signal appear, where did ownership become assumed, who had authority, and what rule should have moved the warning when authority was unclear? When a team leaves with a named receiver, a return date, and an escalation rule, the next few weeks look different. People have something better than a reminder to be brave. They have a path.
The rebuild: from signal to named owner
Most incident frameworks assume ownership already exists. This one exists to create it.
The rebuilt route does not start with another channel. It starts with a lightweight aid that helps a team move a visible warning into explicit ownership. That is why I am giving away the Incident Triage Decision Aid with this article.
The aid asks four routing questions.
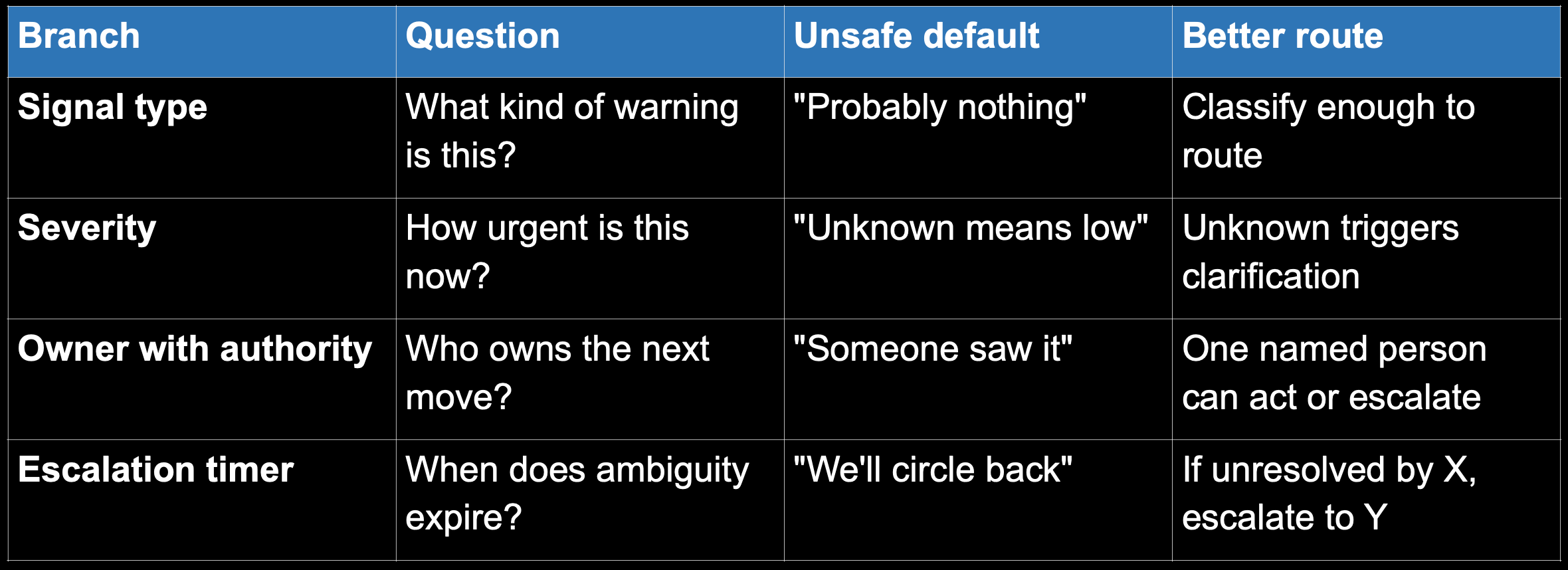
MTTO (time from first visible signal to explicit ownership). Use as a local learning metric, not a personal scorecard. This is the gap the graveyard dashboard was hiding.
Run the Part 1 warning through the aid, and the route becomes visible.
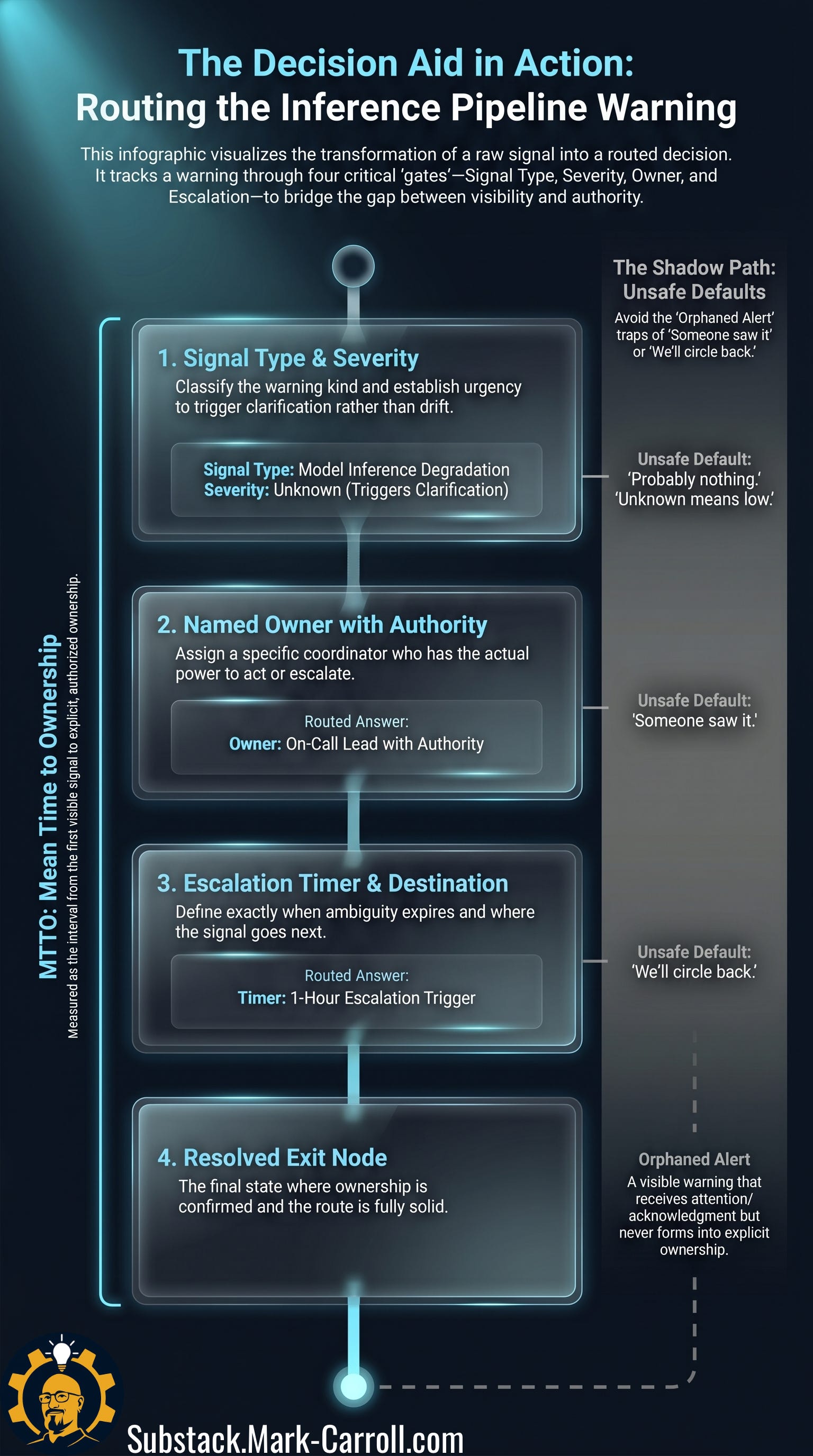
In practice, the first two branches work together: classify the warning and clarify its urgency. When severity is unknown, the correct answer is not drift. It is rapid clarification. The third branch names the owner with authority, because a name without authority creates false ownership. The fourth branch sets the escalation timer and destination, because ambiguity needs an expiration date.
For the inference pipeline warning in Part 1, the rebuilt route might look like this: signal type, model inference degradation; severity, unknown but customer-impacting potential; owner, on-call platform lead with authority to pause the related rollout or escalate; escalation timer, ownership and next action explicit within one hour, otherwise escalate to the engineering manager. That is not a heroic intervention. That is four questions asked before the channel swallows the warning.
Do not use the aid as a replacement for formal incident command in major or regulated response structures. And do not use it to assign fault after the fact. A named owner is a coordination mechanism for the next move, not a retroactive fault label.
I have not always seen the full version of this work as cleanly as I would like. What I have seen are pieces of it work: a blocker policy that forced escalation after a day, a readiness checklist that caught an unowned dependency before sprint commitment, a working agreement that said a repeated warning gets a named owner before the meeting ends. Each one worked for the same reason. It moved the decision out of personal courage and into a shared route. Many warnings drift for social reasons, not technical ones. Nobody wants to overreact, interrupt the wrong person, or turn a weak signal into a fire drill. A lightweight routing mechanism gives the team permission to act without making someone perform urgency. The tool works when it is small, visible, trusted, and attached to a moment the team already inhabits.

Run the five-warning field test
Do not start by redesigning your entire incident process. Start with the next five credible warnings that appear in your workflow. For each one, track when the signal first became visible, when acknowledgment happened, when a named owner with authority claimed it, when the next action became explicit, and whether an escalation timer and destination existed.
Then ask: which warning had the longest gap between visibility and ownership? That is your first route repair. That small exercise will show whether your team has a visibility problem, an acknowledgment problem, an ownership problem, or an authority problem. Those are not the same diagnosis, and they do not require the same repair.
Download the Incident Triage Decision Aid with this article. It is the routing logic this episode diagnoses as missing. Pin it in Slack, add it to the runbook, or print it for the room. The diagnosis is free because a visible warning still needs a route, and the route should not start behind a paywall. Paid subscribers help fund the next round of practitioner tools, field guides, and Route Rebuilder artifacts.

The moment that started this series was quieter than I wish. Nobody slammed a table. Someone wrote “communicate better” on a retro board, and I remember thinking: we have written this before. Not this exact team, not this exact issue, not this exact room, but the same conclusion wearing the same harmless little sweater.
The people in the room cared. They had worked hard. They wanted the next blocked handoff to go differently. But the action item was asking human beings to remember harder inside a route that still had no owner, no timer, and no authority path. That was when I realized the work was not to lecture teams about communication. The work was to rebuild the route.

That realization also sits at the heart of my upcoming book, Collaborate Better. The book is built around the same conviction behind Route Rebuilder: collaboration does not improve because people care harder inside broken systems. Collaboration improves when teams build clearer routes for trust, ownership, decisions, and action. You can learn more at CollaborateBetter.us.
Route Rebuilder starts here because this is the smallest route failure with the biggest consequences. A warning appears. People see it. Everyone assumes the system is working because the channel is active.
But activity is not movement.
The first route to rebuild is the one between signal and ownership.
Because unread messages do not bury bad news.
Unowned warnings do.
P.S. Pull one warning from your last incident review or retro. Ask four questions: When did this become someone’s job? Did that person have authority? Was there an escalation timer? Where should the signal have gone next? If nobody can answer quickly, run it through the Decision Aid before the next review. Then reply and tell me what you found. I read every one.
Next:

Next in The Route Rebuilder: The Route That Made Ownership Optional, where a handoff became a gap when nobody named a receiver.

Previous:

More Content to Discover:



The most expensive incident is often the one everyone saw early.
That sounds impossible until you trace the route: the warning was visible, acknowledged, discussed, and still never reached a named owner with authority to act.
In Part B, I show how that drift becomes Bystander Burn, Investigation Tax, and Compounding Rework, then give you the Incident Triage Decision Aid so your next warning gets a route before it becomes archaeology.
Hi Mark! What stands out right away is your practice of including the research binder. That's very responsible and helpful: a great way to show your work. If you don't mind, I might consider doing something somewhat similar in the future and crediting you for the idea.
I also really like the coinage of "Orphaned Alert." I'm a fan of unique coinages if they're serving a purpose and I think this one does: "orphaned" adds a sense of urgency and makes a complex meaning clear in just two words. It reminds me of Scott Alexander's idea of "concept handles": https://slatestarcodex.com/2016/02/20/writing-advice/#:~:text=9.%20Use%20strong,a%20complex%20topic.
Likewise, I think the block text where you define your other terms is very effective. I think all of the care you take with your language embodies the thesis of the article itself, which I take to be saying that if we don't tie specific language to specific action from a specific person, it can actually mislead more than it informs by making us feel like something is being taken care of when it's not.
It's also a good reminder, because when our work depends on knowledge and communication, producing the knowledge, documentation and the communication often *does* count as a form of action, so it can be easy to get confused about when the communication by itself is not enough.