
When Profit Depends on One Person
The Person Who Saves Every Release Is Not Your Resilience Strategy (Profit With Proof | Episode 8)

The Hero-Mode Premium
Premium artifact: Bus Factor Cost Model (FREE)
The exit interview
👋 Welcome to this week’s edition of Empathy Engine. Every Wednesday (formerly Tuesday), I publish a new article for paid subscribers first, then unlock the full piece for everyone late Thursday morning. Each week, I turn product leadership friction into practical tools, sharper language, and more defensible decisions.
Previous article in this series: Episode 7 (The Profit Your Sprint Plan Already Spent)

The VP of Engineering thought the meeting would be difficult. Difficult would have been anger, accusation, or a senior engineer finally saying the thing everyone else had trained themselves not to hear. This was worse. The principal engineer sat across from them calm, specific, and already gone.
They had been with the company for six years. Long enough to remember the original architecture conversation, long enough to know why billing behaved differently for three enterprise customers, and long enough to know which deployment script could be trusted only if someone watched the logs like a hawk. They did not say leadership had failed them. They simply named the last eighteen months.
Eleven releases where they stayed late because nobody else knew the critical path. Three incidents that never became incidents because they saw the failure pattern before the dashboard did. A legacy service nobody wanted to own, but everybody depended on. A decision history scattered across Slack, memory, and the phrase, “Ask Priya before you touch that.”
The VP heard a resignation.
The system was losing an undocumented operating manual with a heartbeat.
Research Binder: the receipts (citations + source notes) are compiled in a PDF at the bottom of this article.
Names and identifying details throughout this article are changed, but the pattern is real. I have seen teams lose “one person” and then discover they had actually lost the release history, the workaround memory, the stakeholder trust, and the unofficial operating manual. The real cost of replacing them was not their salary. The cost was every decision the organization never bothered to make transferable.

Leadership sees one senior employee leaving. The team sees five invisible systems with no second owner. The bill does not begin when the person resigns. The bill begins when the organization lets one person become the route.
TL;DR
Hero mode is not a personality type. It is a system failure that found a person-shaped workaround. The hero makes the system look reliable while making the organization less resilient. The Bus Factor Cost Model turns invisible dependence into a practical, board-safe resilience conversation, using local assumptions rather than fake universal benchmarks.
If one person saves every release, the organization does not have a hero. It has a single point of failure with good calendar manners.
Hero mode is a system failure with a human face
Most organizations describe hero mode as a talent story. Someone steps up, someone knows the system, someone stays late, and someone saves the release. That version is flattering, incomplete, and expensive.
Hero mode is what happens when the route requires one person to function. The system depends on them because the organization never built the conditions that would let anyone else carry the work. Nobody wrote “make Priya the resilience strategy” on a whiteboard, but the system behaved as though someone had.
This is another broken route problem. The signal exists, the decision history exists, the operational knowledge exists, and the escalation path exists. The problem is that all of it passes through one person. The pattern forms quietly. The first time the hero stays late, people call it commitment. The fifth time, people call it reliability. The fiftieth time, people stop calling it anything because it has become the operating model.
Reliability is not resilience
The hero makes the system more reliable. That is the trap. They prevent incidents, stabilize releases, answer questions nobody else can answer, and make the dashboard look safer than the system actually is. The release shipped. The customer was saved. The metrics stayed green. From the inside, one person absorbed the gap.
I have watched delivery trains report confidence while knowing the actual plan depended on a few people privately reconciling dependencies the official board made look solved. The metrics were not useless, but they were incomplete. They showed the plan people had agreed to. They did not show the hidden human labor required to make that plan survivable.

Management sees green dashboards, a praised hero, and “great work, team.” The team lives one person online at 2:00 AM, Slack archaeology for rollback scripts, and architecture decisions that still require a human oracle. Reliability asks, “Did we ship?” Resilience asks, “Could we ship without them?”
That distinction matters because reliable systems can still be fragile. Every rescue can increase confidence in the result while decreasing resilience in the route. The organization praises the firefighter, then quietly builds more of the building out of matches.
The hidden dependency map
The real dependency map does not appear in the org chart. It appears in patterns: who gets called when the release breaks, who knows why the workaround exists, who remembers which customer exception changed the architecture. That map usually carries three kinds of knowledge.
System knowledge: legacy services, release scripts, migration history, and operational folklore that never made it into the official runbook. Decision knowledge: why a technical compromise exists, why a customer exception became permanent, and why one old service still behaves like a haunted filing cabinet. Rescue knowledge: incident intuition, rollback judgment, escalation shortcuts, and the “I know who to call” memory that saves hours when something breaks.
The hero does not only know the system.
The hero knows the organization’s memory of the system.
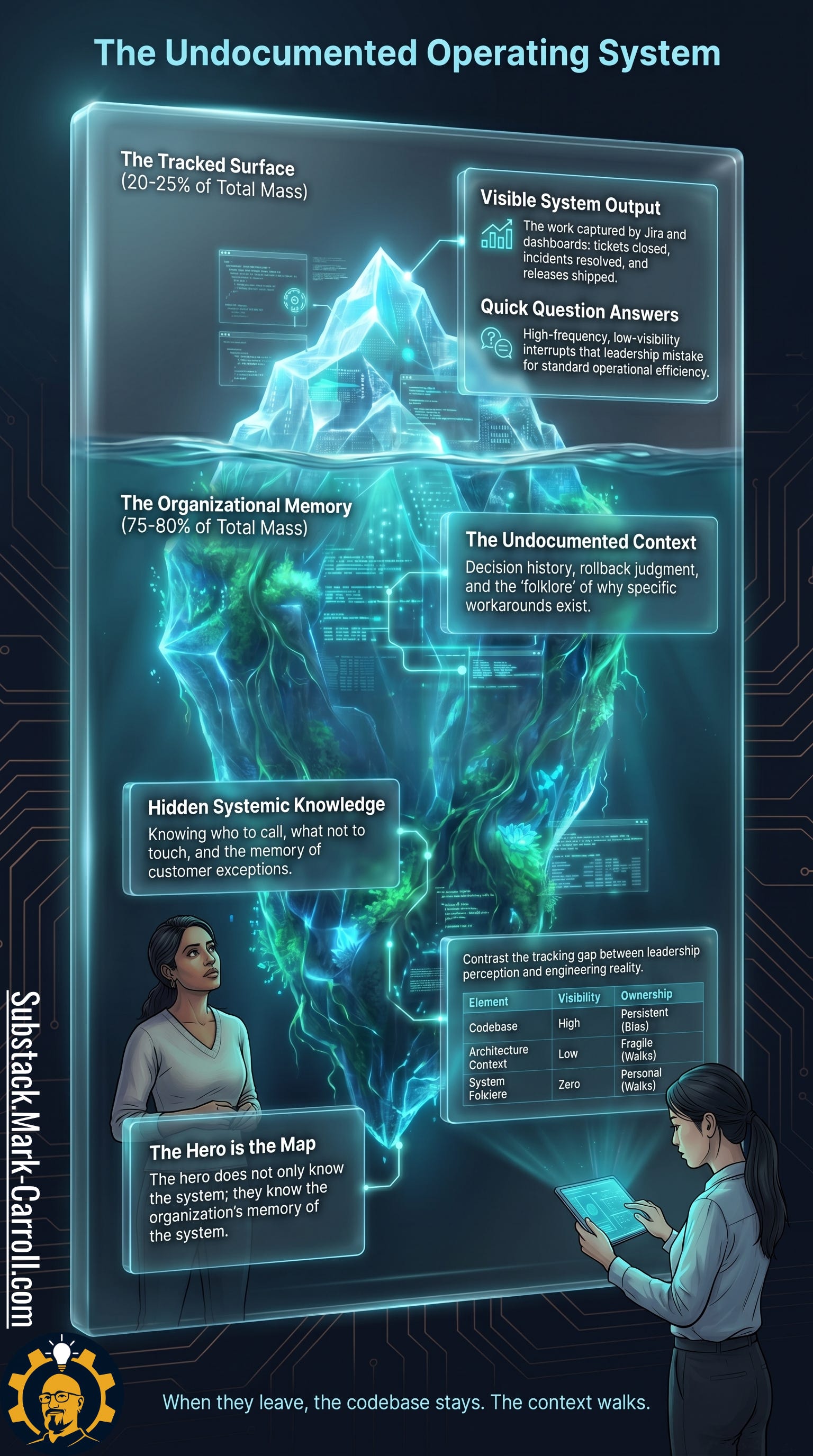
The tracked surface is visible: tickets closed, incidents resolved, releases shipped. The organizational memory is harder to see: decision history, rollback judgment, folklore, and the quiet knowledge of what not to touch. When they leave, the codebase stays. The context walks. You can hire another principal engineer. You cannot instantly hire six years of local memory, political context, customer scars, and operational judgment. Recruiting replaces capacity. Knowledge transfer restores continuity.
The season lands here
Profit With Proof has spent seven episodes pricing costs organizations hide from themselves. The Rework Tax priced ambiguity.

The Escalation Delay Cost priced silence.

The Churn You Can Predict priced ignored signals.

The Compliance Theater Budget priced controls that photograph well but do not work well.

The Integration Penalty priced tool rollouts that never became adoption.

The Agile Meeting Burn Rate priced coordination theater.

The Ghost Capacity Trap priced the hours the spreadsheet pretended did not exist.
Episode 8 names the person who absorbed those costs until the system mistook their exhaustion for resilience. Even if this is your first Profit With Proof article, the pattern is simple: every hidden cost survives longer when one person quietly absorbs it. The hero’s nights and weekends became the missing capacity the spreadsheet never counted. That is the capstone logic. The first seven costs were survivable because someone absorbed them. That someone is now in the exit interview.
The comfortable dependency trap
Here is where this gets uncomfortable. A team can be psychologically safe enough to admit the problem and still not be structured to survive it. Many leaders assume that once people feel safe to speak up, the system will naturally improve. That is only half true.
Psychological safety, as Amy Edmondson’s work defines it, tells us whether people feel safe taking interpersonal risks, asking for help, admitting mistakes, and raising problems. In hero-mode teams, that climate matters because someone must be able to say, “We are one person away from a serious delivery failure.” But psychological safety is not the same thing as structural resilience.
A team can trust the hero, admire the hero, and feel safe asking the hero for help. A team can be kind, warm, collaborative, and deeply fragile. That is what I call comfortable dependency: an editorial label for a pattern the research indirectly points to but has not named as such. The term is doing narrative work here, not scientific work.
I have been in rooms where everyone believed the team could handle whatever came next, but once we got specific, the plan quietly depended on Sarah knowing the deployment path and Miguel knowing the one integration nobody else could safely touch.

The dangerous quadrant is the comfortable one: the hero is trusted, everyone knows who to ask, and nobody pushes hard enough to change the structure. The answer is not “build psychological safety” and declare victory. Safety opens the conversation. Structure changes the system.
Where the time goes
Hero mode is often described as dramatic. Sometimes it is: a Sev 1 incident, a late-night rollback, a deployment that survives because one person knows which sequence of scripts and prayers will keep the system upright. Most of the time, though, hero mode is not cinematic. It is fragmented, interruptive, and boring in the way only chronic organizational failure can be boring.
There was a period where my calendar said coaching and facilitation, but the actual work was being human middleware for Sarah, James, and Priya as they tried to reconcile the official process with the work the team actually had to survive. Every interruption felt reasonable in isolation. Together, they became a one-person rescue operation.
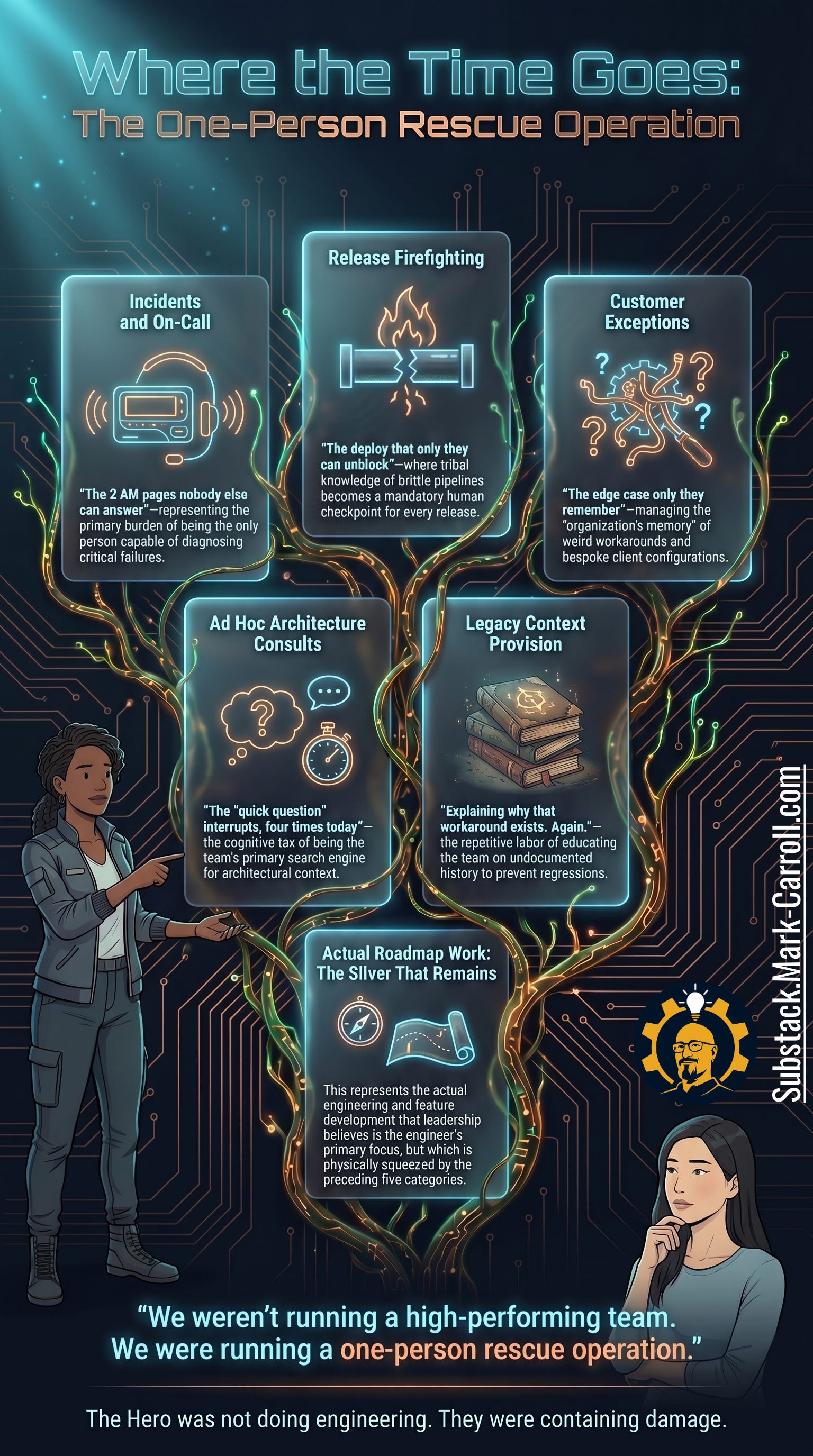
Incidents and on-call, release firefighting, customer exceptions, ad hoc architecture consults, legacy context provision, and actual roadmap work squeezed into whatever oxygen remains. The hero is not only doing extra work. They are losing the conditions required to do the work leadership thinks they are paying them to do. When leaders ask why the roadmap is slipping, the answer may be sitting in five categories of invisible labor. That is not productivity. That is containment.
What the evidence actually lets us price
Now we can talk about money. Not first. Now. Profit With Proof has one job: name the hidden cost, price what can be priced, and refuse to launder folklore into finance.
The tempting move would be to say, “Replacing a senior engineer costs three times their salary,” then build the whole argument around that number. That would be convenient. It would also be too soft. The evidence review found no strong, role-specific basis for treating “3x salary” as a universal benchmark for senior technical replacement cost. No borrowed benchmark should be allowed to wear a cape indoors.
The safer frame is this: the model does not tell you what every hero costs. It helps you price what your organization has chosen to leave concentrated.
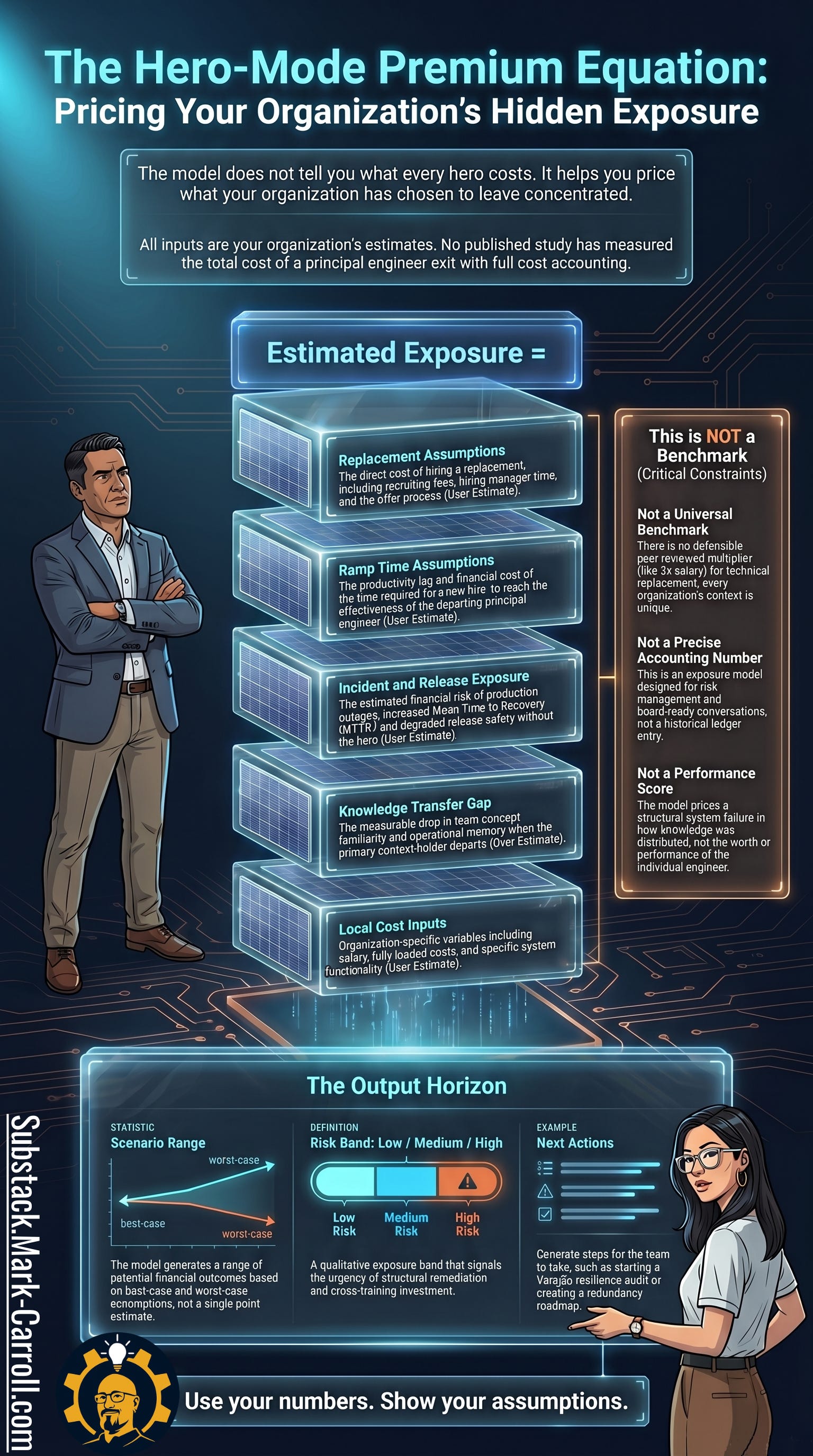
The equation is built around user-supplied assumptions. Estimated exposure includes replacement assumptions, ramp time assumptions, incident and release exposure, the knowledge transfer gap, and local cost inputs. The output is a scenario range and a risk band, not a universal benchmark, not a precise accounting number, and not a performance score. That distinction is not academic. It is the difference between a model a CFO can challenge productively and a model they can dismiss in twelve seconds while adjusting their glasses.
The strongest financial context belongs at the macro level: industry-level estimates put the cost of poor software quality in the trillions, but those figures are modeled context, not audited line items and not a bus-factor benchmark. Hero-mode dependency is one local mechanism by which operational fragility stays hidden until it becomes expensive. Those macro numbers tell you there is a lot of money on the table, not how much any single hero costs.
The Bus Factor Cost Model and what leaders should do next
The Bus Factor Cost Model is a resilience inventory (available bottom of this page for download). It is not a hero detector, an HR instrument, or a surveillance dashboard for ranking “risky employees,” a phrase that should be taken outside and made to think about what it has done. It asks leaders to define one scope: one system, service, or release path where everyone already suspects the same person gets called. Then it asks practical questions. Who can execute this path end-to-end? Is the runbook current? Is there a backup owner?
The Varajão team resilience model is useful here as a supporting diagnostic, not as a financial benchmark. Scorecard here means a small set of questions and observations, not a numeric performance score. It gives leaders language for the underlying resilience factors, including trust and solidarity, management and accountability, and skills and behaviors.
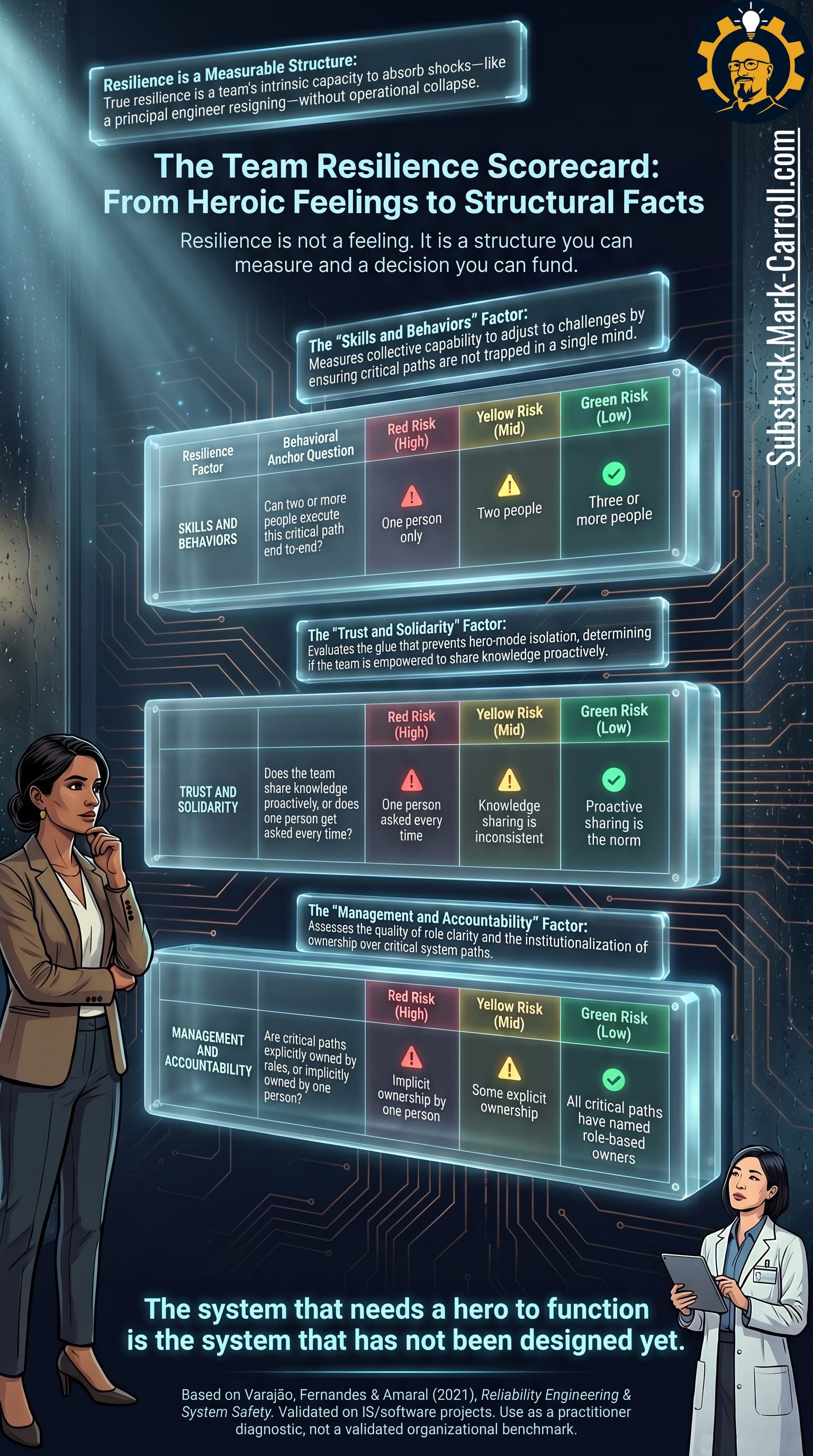
Do not start with the whole organization. That is how practical ideas go to die in a steering committee wearing loafers. Start with one critical release path. Name the person-shaped dependency without blaming the person. Write, “The release rollback process depends on knowledge currently concentrated with Priya.” Assign a backup owner. Not a vague team, not “engineering,” and not “platform will handle this,” which often means “a meeting will absorb this concern until everyone forgets why it mattered.” A named person needs hands-on capability.
Create one transfer artifact per dependency: a runbook, decision record, pairing session, or incident replay. Then give the work time. Do not punish the hero by turning them into a documentation factory. Knowledge transfer is not extra work. Knowledge transfer is the work that proves the organization actually wants resilience. In one fictional example, a single rollback dependency moved from red to yellow in thirty days, without adding headcount. That is what measurable reduction looks like. Treat whatever numbers you get as inputs to a conversation, not as the final answer your finance team should book into a model.

Do not use this model for performance reviews, compensation discussions, blaming the hero, ranking risky employees, declaring precise dollar costs, or during a live incident. Use it for QBR prep, succession planning, incident retrospectives, capacity planning, roadmap risk reviews, and resilience investment discussions.
The Bus Factor Cost Model prices structural dependency, not a person’s worth. The system created the dependency. The person absorbed the cost.
The cost of gratitude without design
Return to the exit interview. The engineer leaves. The VP finally understands the cost, but too late. The releases were stable, the incidents were avoided, the customers were protected, and the dashboards stayed green.
The organization called that performance. The engineer called it exhaustion.
Hero mode is expensive because it hides the bill until the person carrying it stops carrying it. That decision to depend on one person often looks rational in the moment. Ask the hero, move faster, save the release, keep the customer calm, skip the documentation, and promise to fix the structure later. Later becomes next quarter. Next quarter becomes after the migration. After the migration becomes once hiring improves.
That is the premium. Not the salary, the recruiter fee, or the replacement timeline alone. The premium is the accumulated cost of every dependency the system normalized because the hero kept making the consequences invisible. The person who saves every release is not your resilience strategy. They are the receipt for the one you never built.
Earlier in my career, I wish I had understood that gratitude can become an exceptionally polite form of avoidance. If Sarah is saving every release, thanking her is not the same as redesigning the system so she does not have to.

That is also the larger case behind my upcoming book, Collaborate Better. Better collaboration is about designing systems where responsibility, knowledge, and decisions do not collapse onto the same exhausted person. When collaboration fails, people absorb the damage. When collaboration works, the route survives without requiring a hero every Friday night. Learn more at CollaborateBetter.us.
Premium artifact (FREE)
Here’s the Bus Factor Cost Model. It helps engineering and product leaders inventory key dependencies, estimate exposure using local assumptions, and identify the top knowledge-transfer actions that reduce hero-mode risk.
This model helps you ask the questions your dashboards cannot answer: who actually carries the critical path, what would fail if they were unavailable, and what transfer work would reduce the exposure before the exit interview.

The Route Rebuilder begins next
Profit With Proof was about naming the dollar value of operational failure. The Route Rebuilder moves to the next question: once you can see the cost, how do you rebuild the route that created it?
This next series is for engineering and product teams living inside real organizational systems: incident channels that bury warnings, handoffs that make ownership optional, review gates people learn to skip, velocity metrics that hide rework, AI tools that quietly absorb judgment, and pressure-tested routes that survive because someone designed them to survive.
The thesis is simple: every failure is a broken route, and every broken route has a rebuild.
That is the bridge from this episode. Hero mode is what happens when the route through the system becomes a person. The Route Rebuilder asks what comes next: how to name the broken route, redesign the decision path, and ship a practical tool the team can use before the next sprint, incident, or launch turns theory into consequences.
P.S. If your resilience plan has a first name, a Slack handle, and a vacation calendar everyone fears, which critical path will you inventory first?
Regards,
Mark 👋
Empathy Engine | Substack.Mark-Carroll.com | Evidence-Forward Product Leadership

Previous:

More Content to Discover:


The scariest dependency in your organization probably does not look like a risk.
It looks like the person everyone trusts.
The person who knows the release path.
The person who remembers the customer exception.
The person who can explain why the old workaround still exists.
That is what makes hero mode so dangerous. It feels safe right up until it does not.
In this piece, I’m asking a question every engineering and product leader should be able to answer before the resignation notice arrives:
If the person who saves every release disappeared for 30 days, what would your team suddenly discover it never actually knew?
Drop the first critical path that comes to mind. Not the person’s name. The path.