
The Route That Buried Bad News
The Signal Didn’t Die, The Route Did (Route Rebuilder| Episode 0)

The Signal Didn’t Die. The Route Did.
The Route Rebuilder begins with the moment everyone saw the warning and nobody owned what happened next.
👋 Welcome to this week’s edition of Empathy Engine. Every Wednesday, I publish a new article for paid subscribers first, then unlock the full piece for everyone late Thursday morning. Each week, I turn product leadership friction into practical tools, sharper language, and more defensible decisions.
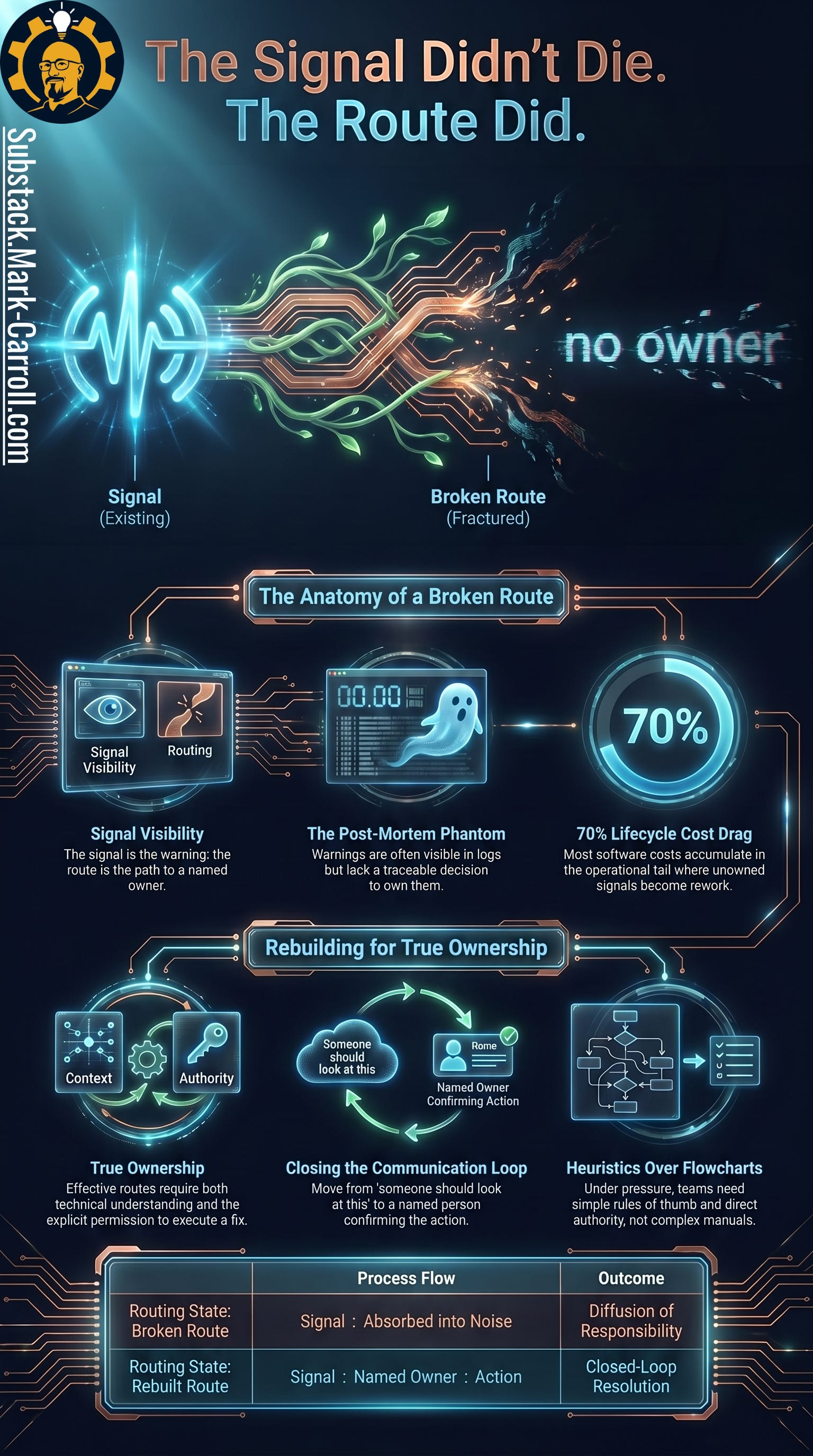
The Warning Was There
Research Binder: the receipts (citations + source notes) are compiled in a PDF at the bottom of this article.
A senior engineer drops a warning in the incident channel. There is an intermittent failure in the inference pipeline. The channel already has 847 unread messages. The warning lands, someone sees it, and the day keeps moving.
Fourteen days later, the team is in the postmortem, scrolling back through the noise. The warning is right there. Timestamped, visible, and maybe even acknowledged. Nobody can answer the harder question: when did this become someone’s job?
That is where The Route Rebuilder begins. Not with blame. Not with another dashboard. Not with a heroic speech about accountability delivered in the tone of someone who has never had to find a missing Jira ticket at 11:47 p.m.
The uncomfortable truth is simpler. The signal was there.
The team was there. The route was not.
I have been the person scrolling back through that channel. I remember seeing an alert on a Tuesday afternoon that looked like one of those transient errors that clears itself before anyone has to care. I even remember thinking, “That is odd,” then going back to sprint review prep. When it came up in the postmortem two weeks later, I felt my stomach drop because I knew I had seen it. The worst part was not that I missed it. The worst part was realizing I had quietly decided it belonged to someone else.

If you are skimming:
The signal was visible. The owner was not. That gap is the broken route. This article gives you the language for the series and one question you can use in your next review. If you are short on time, read the next section and the Broken Route Finder box, then skip to Part 1 Begins Here.
The Gap Between Seeing and Owning
A lot of organizational failure hides inside one small assumption: if people can see the signal, then someone must be handling it. That assumption feels reasonable until the postmortem proves otherwise.
Teams often confuse visibility with movement. A dashboard makes the signal visible. A channel makes it discussable. Neither guarantees that the signal has moved to the person who can decide and act. Everyone knows enough to feel concerned. Nobody knows enough to feel responsible. The organization is aware, but the next action is still floating around the room like a ghost with calendar access.
I once sat in a program review looking at a dashboard with every project marked green, yellow, or red. It had dates, categories, dependencies, and a beautiful executive summary. Then someone asked, “Who owns the next action on the yellow items?” The room got quiet. That was when I realized the dashboard was tracking concern, not ownership.
The issue is not always that nobody said anything.
The issue is that what was said never traveled through a working path from signal to decision to action.

Receiving Is Not Routing
A signal can be a warning, a ticket, a customer complaint, or the quiet risk someone raises before everyone moves on. A route is the path that moves the signal from visibility to a named owner with the authority to act. A broken route is what happens when that path exists in theory but not in practice.
Here is the difference in one line. A signal has not been routed because someone reacted to it, dropped an emoji under it, or said “Good catch.” A signal is routed when someone owns the next move.
The language for this series:
Route: the path from signal to decision to action.
Broken route: when the signal is visible but never reaches a named owner with authority.
Rebuild: a lightweight mechanism that makes the next move obvious. Later episodes will ship one per episode.
Pressure test: the real-world moment that reveals whether the route works when stakes rise.
Here is the broken route in one line:
Signal → channel → acknowledgment → assumption → drift → postmortem.
Here is the rebuilt route:
Signal → named owner → decision → next action → escalation timer.
That single contrast is the lens for this entire series. A route that only works during planning is a hope, not a route.
The Broken Route Finder (Free for All Subscribers)
You now have the vocabulary. The next step is aiming it. Without a diagnostic, most teams default to fixing the loudest problem rather than the most expensive one.
The Broken Route Finder is a one-page diagnostic that walks you through six observable symptoms. The kinds of things that surface in incident reviews, sprint retros, and quiet hallway conversations and helps you identify which type of routing failure your team is living with right now.
Each symptom maps to one of the six episodes in this series. You do not need to read every episode to get value. You need to start with the one that matches your team today.
It takes ten minutes. It requires no preparation, no facilitator, and no meeting about the meeting. Download it, run it before your next review, and pick the symptom that makes you wince. That is your first broken route.
This is a decision-grade diagnostic tool. The kind of artifact that would normally sit inside a consulting engagement alongside a strategy offsite. It is free for every subscriber because the goal of this series is not to gate the diagnosis. The goal is to make sure the diagnosis reaches the people who can act on it.
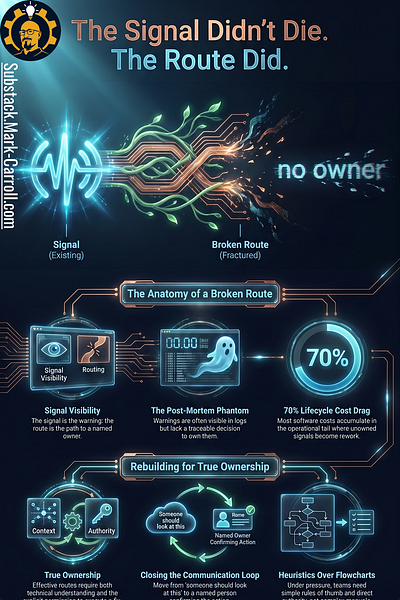

Why Broken Routes Get Expensive
Broken routes rarely announce themselves as strategy problems. They show up as rework, cleanup, firefighting, delayed decisions, and that special corporate ritual where everyone stares at the same old message and pretends the timestamp is not judging them. The bill arrives anyway.
Empirical software engineering research suggests that more than 70% of many systems’ lifecycle cost lands in maintenance and operations, not in the launch week.
That is the long tail where warnings that never find an owner turn into rework, firefighting, and slow drag on the team. The claim is not that broken routes cause all of that cost. The claim is simpler: when signals fail to move early, they often become more expensive later.
I once traced a single unrouted warning through four weeks of downstream work. It had been listed as a minor risk in a weekly status update for a month. The original fix would have been one decision in week one. Instead, the cleanup took two engineers for six days, one QA analyst for three days, a PM rewriting scope, support drafting customer messages, and leadership asking for updates twice a day. We did not save time by waiting. We just moved the cost to more calendars, more Slack threads, and more meeting invites.
This is why the Route Rebuilder starts before the disaster. A route is easiest to repair before the incident, before the escalation, before the customer impact. Once the work has entered the long tail, the team is no longer preventing cost. The team is negotiating with it.
That is also why “we have tools for this” is only half an answer. Tools can capture, alert, assign, and archive. Those are useful jobs. The harder question is whether the organization has a working path from “we can all see this” to “one person clearly owns what happens next.”

This Is Not a People Problem
Broken routes are usually not one person’s fault. Fast-moving teams add tools, alerts, channels, tickets, and dashboards faster than they add clear paths from “I see it” to “I own it.” The result is not apathy. The result is a system full of responsible people surrounded by unclear handoffs.
That is why blame is such a poor repair tool. Blame makes people hide signals, defend themselves, or wait for someone safer to speak first. Blame can produce a name, but a name is not always a route.
I have watched this play out. A manager was pushed out after a delivery miss. The story became that they had failed to coordinate the handoffs. What nobody traced was that the handoffs were never designed. The dependency map was vague, receiving teams had no named owners, and the escalation path depended on personal relationships. The organization changed the actor and kept the script.
A competitor hired the original manager within a month, with a pay increase (which should have been the first clue that the problem was not individual competence). Three months later, the new manager hit the exact same dependency miss. Same teams. Same handoff gap. Different name on the escalation thread. The system did not get safer. It just got more careful about leaving fingerprints.
The better question is not, “Who dropped the ball?” The better question is, “Where did the ball stop moving?” That question changes the room. It points attention away from character and toward design.
A broken route does not mean nobody cared. It means the organization had not yet built a reliable path for the signal to travel. That is a much more useful problem because useful problems can be rebuilt.

If the gap between seeing and owning sounds familiar beyond incident channels (in how teams collaborate, escalate, and make decisions together) that is the territory Collaborate Better was written for. Collaboration is not just people being nicer in meetings. It is the design of the paths people use to notice, decide, and act together. CollaborateBetter.us

From Profit With Proof to Route Rebuilder
Profit With Proof was about pricing what teams usually ignore. Rework. Escalation delay. Predictable churn. Compliance theater.




The Route Rebuilder asks the next question. Once we can see the cost, what route do we rebuild? Naming the waste is useful, but naming the waste is not enough if the same signals keep entering the same broken paths.
That is the shift. Profit With Proof helped expose the bill. The Route Rebuilder follows the signal back through the organization to find the missing path that created the bill in the first place.
Part 1 Begins Here
I built this series because I kept finding myself in the same room with different people. Different company, different tool stack, different org chart. Same silence when someone finally asked who owned the next action. The warning had been there. The ticket had been there. The dashboard had been there. Everyone could point to the moment the signal entered the system, but nobody could point to the moment it became someone’s job.
That pattern costs teams more than money. It costs trust. It costs weekends. It costs good people their confidence because they start wondering whether they missed something obvious (when the truth is worse: the organization had no route for the signal to travel). I built The Route Rebuilder because I am tired of watching teams pay emergency prices for problems they could have handled early.
Part 1 begins back in that incident channel. Fourteen days of drift, one warning that never became someone’s job. The channel received the warning. The route never moved it.
In the first episode, we will look at the route that buried bad news. We will ask how an organization can receive a warning and still fail to move it. And we will begin shaping the first rebuild: a way to move from signal to severity to owner to escalation before the postmortem has to reconstruct the crime scene.
The Route Rebuilder Starter Kit (Free for All Subscribers)
Episode Zero gives you here the lens. The Starter Kit gives you the first set of working tools.
Inside: a Route Diagnostic Card, a Receiving Is Not Routing explainer, five copy-paste Signal Routing Prompts, a Team Discussion Guide, and a Route Trace Template.
Use it in a live conversation, not after the fact. Pick one real signal, trace where it entered, name who owns the next action, and decide whether the route is broken, rebuilt, or still untested.
Everything fits on a single page or screen. No training, no configuration, and no meeting about the meeting.

The Series Ahead
This series follows the same failure pattern through six different rooms: the incident channel, the ownership handoff, the review gate, the velocity dashboard, the AI workflow, and finally the route that survived pressure.
This is not a postmortem archive or a framework deck. Each episode starts in a room you will recognize and ends with one tool you can use before the next incident.
Each episode will name the broken route, show why the route failed, and ship one practical rebuild you can use in a sprint, retrospective, incident review, or leadership conversation.

Public posts in this series will name the broken route and show why it failed. Paid dispatches go one layer deeper with the practical rebuilds: decision trees, checklists, and operating prompts you can adapt for your own team.
Part 1 ships next week with the first rebuild: the Incident Triage Decision Tree. A one-page decision tool designed to be pinned in your incident channel before the next postmortem writes itself. Paid subscribers receive the Leader’s Dispatch for each episode: the decision tool, the field notes, and the practical prompts designed to help you bring the rebuild into your next real conversation.
At your next incident review or planning meeting, choose one warning and ask out loud: can we trace the route from the first signal to a named owner to the next action?

If the answer is no, the signal was not the problem.
The route was.
P.S. Have you ever found the original warning during the postmortem and realized nobody could name when it became someone’s job? Reply and tell me what you found. I read every one.
Evidence note
The lifecycle-cost figure is based on empirical software-engineering research showing that more than 70% of many systems’ total lifecycle cost occurs during maintenance and operations (IEEE Transactions on Software Engineering, 2023). This is used as a phase-of-cost anchor, not as a claim that broken routes cause 70% of software cost.
The Route Rebuilder · Episode 000
Next: Part 1 of 6 — The Route That Buried Bad News


Previous:

More Content to Discover:


Have you ever found the warning after the damage was done?
Not a vague “we should have communicated better” warning.
The actual warning.
The ticket.
The thread.
The dashboard note.
The quiet comment in the meeting.
The signal was there. People saw it. Maybe they even reacted to it.
But nobody could answer the question that mattered:
When did this become someone’s job?
Reply with the moment you realized the problem was not visibility.
The route was broken.