
The Escalation Delay Cost
Profit With Proof | Episode 2

The Escalation Delay Cost
If you are skimming
Read three sections: What the evidence actually lets us price, Recovery time is often not repair time, and What leaders should do next. That is the operational spine.
TL;DR
Escalation delay = the gap between first credible signal and named owner with authority to act.
Most downtime is operational and procedural not dramatic. The evidence supports this consistently.
The defensible cost model: delay hours × loaded labor rate × responders affected (plus your own contract terms, if real).
This article does not claim a universal dollars-per-minute benchmark. It gives you the structure to price your own.
What this article does / does not claim
Does: give you a defensible way to estimate your own escalation delay cost.
Does not: claim a universal software cost-per-minute number, guaranteed ROI, or any result that does not come from your own data.
Research Binder: the receipts (citations + source notes) are compiled in a PDF at the bottom of this article.
Previous article in this series: Episode 1 (The Sprint Stayed Green, The Budget Didn’t)

A senior engineer flags a performance degradation in a critical service. The issue lands on a weekly sync agenda. The meeting runs long, the item gets bumped, and nobody formally disputes the priority call. Because it is just a flag, not yet a crisis. It gets bumped again the following week for the same reason. On day nineteen, the degradation becomes an outage. Later, in the postmortem, nobody disputes the timeline. The original warning is right there in the ticket history. Everyone can see exactly when the signal appeared. Everyone can see when the outage arrived.
Almost nobody can tell you what the silence in between was worth.
That silence is the real subject here. And the most expensive part of many incidents is not the outage itself. It is the gap between the warning and the owner.
I have watched this pattern play out in organizations with excellent engineers, mature monitoring stacks, and blameless postmortem cultures. The alert fired. The talent was present. But the routing authority was absent and the fifteen or thirty minutes of polite ambiguity about who should own the next action cost more than the technical fix that followed.
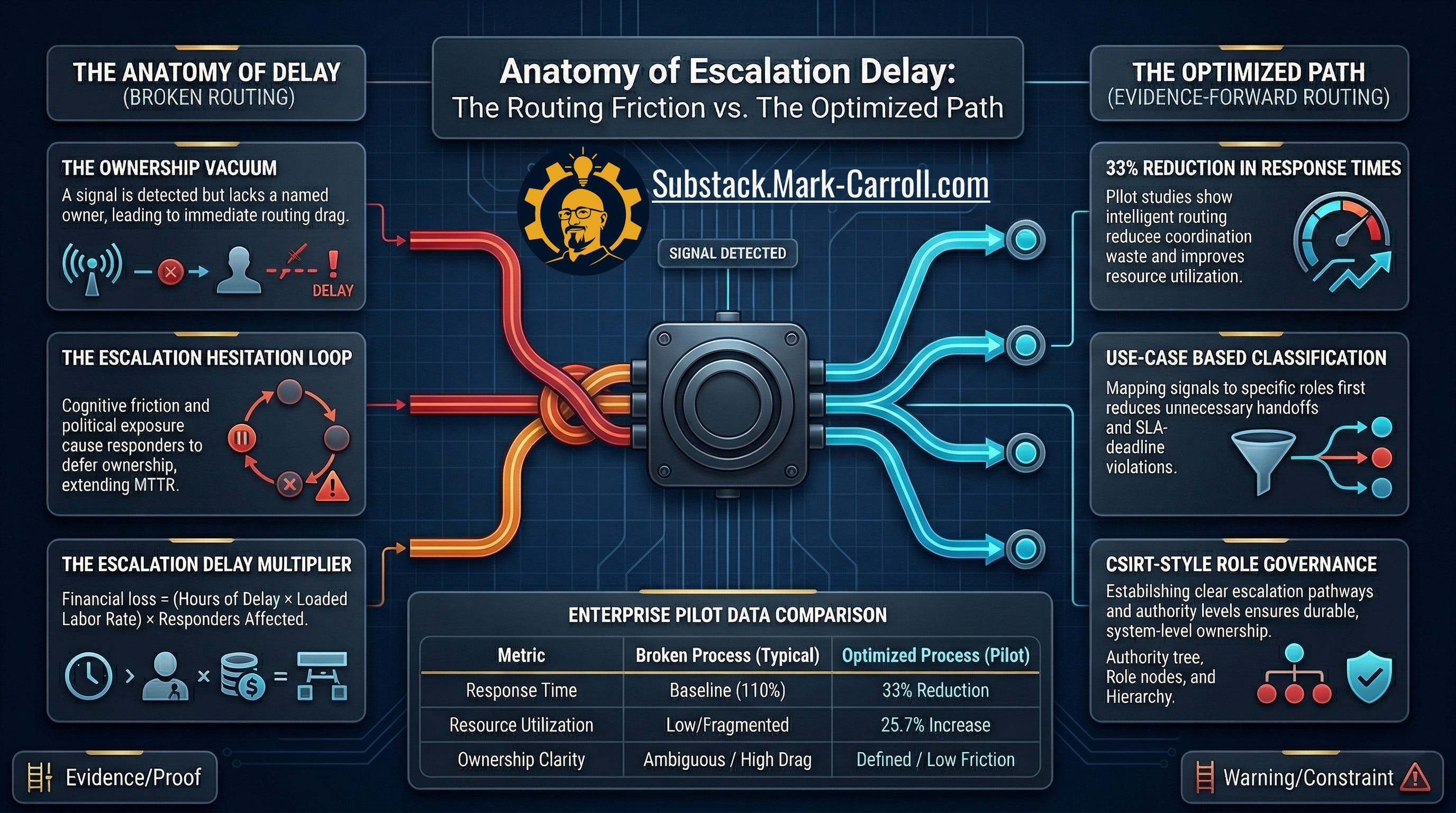
The route broke before the outage began
Most teams know how to talk about incident duration. Mature teams can talk about mean time to recovery. Some can talk about alerting quality, observability coverage, or on-call discipline. Far fewer can talk clearly about the cost of escalation delay. The gap between the first credible warning and the moment a named owner has the authority to act.
That gap is not empty. That gap is where the cost compounds.
In that interval, teams misread signal as noise. Meetings reward order over routing. A growing operational problem gets treated like tomorrow’s inconvenience instead of today’s decision. The warning is visible but the route to authority is broken.
“Routed to the wrong person, or has an unclear scope.” Atlassian incident management glossary, on the most common cause of escalation drag
This is why escalation delay deserves to be separated from outage duration. Outage duration measures the visible problem after the organization admits it has one. Escalation delay measures the silent interest charged before the incident is officially born.
It is also why the issue should be framed as a system cost, not a character flaw. The problem is rarely that one person failed to care. The problem is that the route from warning to authority was vague, slow, or politically expensive to use. A clean postmortem can reconstruct that route later. That does not mean the organization ever priced it while it was happening.
Why this is more expensive now than it used to be
Lean teams, compressed review cycles, and tighter budget scrutiny have made one old habit materially more dangerous: letting a real warning drift without a named owner. When labor is tight and every interruption is expensive, delay is no longer a soft process inconvenience. It is budget leakage.
There is also a structural gap most postmortems quietly reveal: nearly every incident review can reconstruct when the monitoring system first flagged the anomaly. Almost none can quickly tell you when a human being took authoritative ownership of the next action. That is not a historical failure pattern. That is a current instrumentation gap and until you close it, you cannot price it.
What the evidence actually lets us price
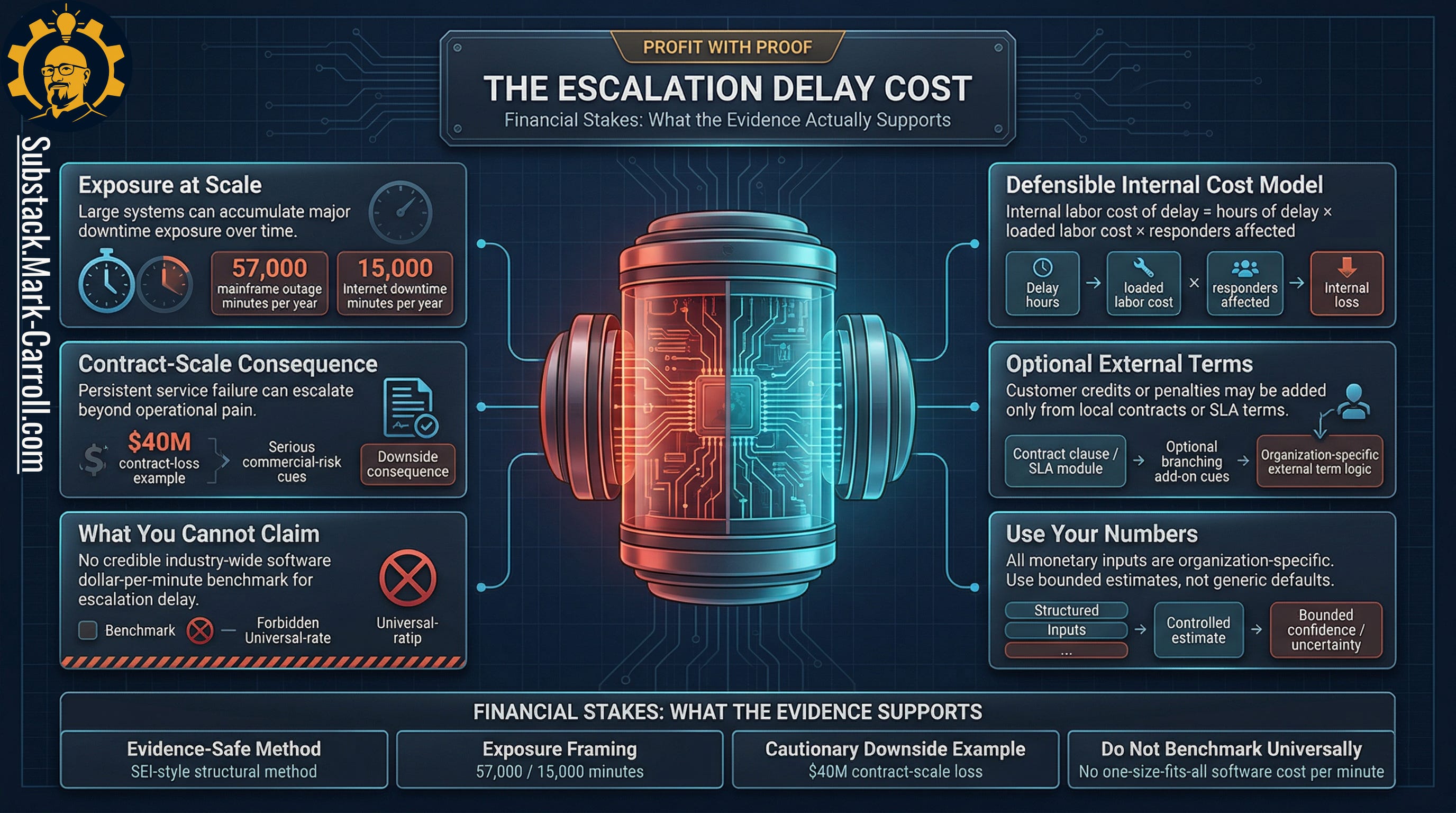
This is where most articles get sloppy. The evidence does not support a universal software dollars-per-minute benchmark for escalation delay. There is no clean public number you can borrow, place into a chart, and treat like revealed truth. You have likely seen those slides, the ones that claim $X per minute of downtime applies to your organization. They rarely survive a real question from finance.
What the evidence does support is a structural model that is weaker in its claims and far more defensible in practice.
The defensible cost structure
The base internal cost of delay:
Hours of delay × Loaded labor rate × Responders affected
External exposure (SLA credits, contractual penalties) should be added only when those terms come from your organization’s actual contracts and realities. Do not import generic vendor benchmarks.
Illustrative math (fictional numbers, clearly labelled)
If a warning drifted for 3 hours before ownership was explicit, with 4 people eventually pulled into the response at an average loaded rate of $150/hour, that interval alone represents roughly $1,800 of internal time — before any customer impact, SLA exposure, or credits. Your numbers will differ. The structure will not.
That may sound less dramatic than a benchmark. It is much more defensible and it forces a healthier conversation. Instead of pretending every minute of delay costs the same everywhere, leaders have to ask the questions that actually matter: How long did the warning drift before ownership became explicit? How many people were pulled into the response once the issue matured? What did that diversion cost internally? What external exposure became real only because the signal sat in limbo too long?
Those are not vanity questions. Those are operating questions. And they correspond almost directly to the four inputs of the structural model: delay interval, responders affected, loaded labor rate, and local contract exposure.
Recovery time is often not repair time
One of the most useful figures in the evidence base sharpens the article’s central point. A reported SEI estimate (useful as contextual evidence rather than a universal preset) suggests that roughly 80 percent of MTTR can be consumed by non-productive activity, particularly identifying which change caused the problem. That number is historical, not a current benchmark, and should not be treated as one. But the implication is hard to ignore.
If a large share of recovery time is consumed by coordination, identification, waiting, and wrong-team routing before meaningful repair work begins, then escalation delay is not a minor pre-incident annoyance. It is a major contributor to the shape and cost of recovery itself. The expensive part may already be compounding before the outage is officially declared.
Engineers often describe this problem in operational language: alert fatigue, unclear ownership, too many handoffs. Leaders and finance partners need a second translation layer: idle payroll bleed, coordination waste, contract exposure. The facts do not change. The vocabulary does and giving leaders the right vocabulary is how engineering friction gets turned into funded budget conversations.

Downtime is usually more operational than dramatic
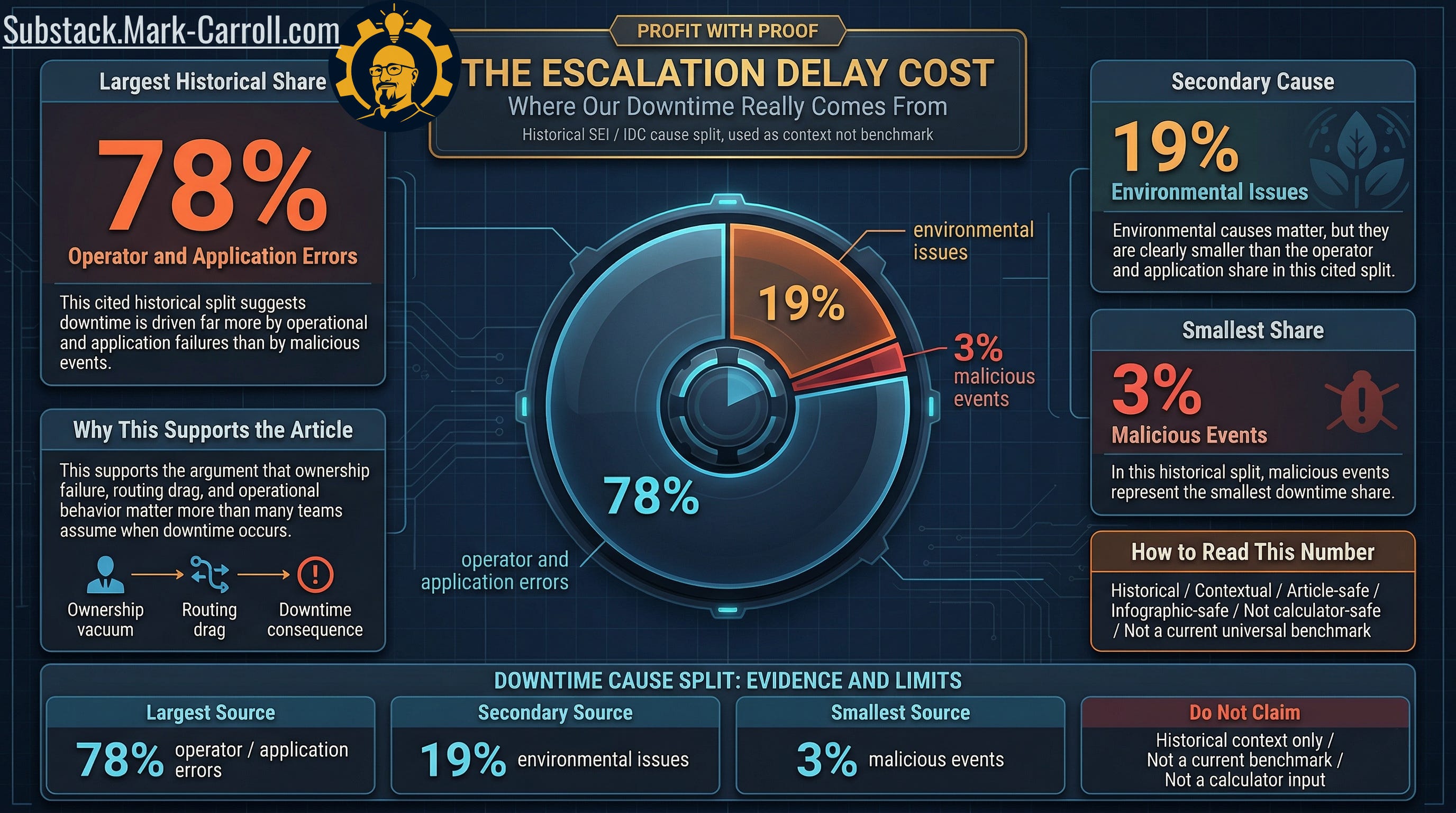
Another historical signal helps correct a very common mental model. In one widely cited cause analysis, roughly 78 percent of downtime was attributed to operator and application errors, about 19 percent to environmental issues, and only about 3 percent to malicious events. The evidence classifies this as historical and contextual not a current universal benchmark and it should be read accordingly.
That still matters, because when people hear “downtime risk,” they often imagine spectacular external events. In practice, the more expensive pattern is consistently operational and procedural: ownership ambiguity, routing drag, delayed authority, application failure, human coordination under stress.
That is exactly why escalation delay deserves to be priced. The dramatic story may be more entertaining. The operational story is usually more expensive.

Better routing can recover time but do not oversell it
The point of this article is not to document failure. It is to show that earlier ownership and cleaner routing can materially change outcomes.
The strongest upside figures available come from a single enterprise pilot study (reported in one intelligent incident-management research paper) showing a 33 percent reduction in response time and a 25.7 percent increase in resource utilization. That is enough to prove that better routing and escalation structure can recover meaningful capacity. It is not enough to justify generic promises or default assumptions for your organization.
A defensible estimate beats false precision. A directional gain beats a fake guarantee. Better escalation design can reduce coordination drag. Cleaner ownership can recover internal capacity. None of that means every organization gets the same outcome, at the same scale, on the same timeline.

What an evidence-forward response path looks like
The most useful response to escalation delay is not a lecture about communication culture. It is a sharper operating path. Here is what that looks like in practice.
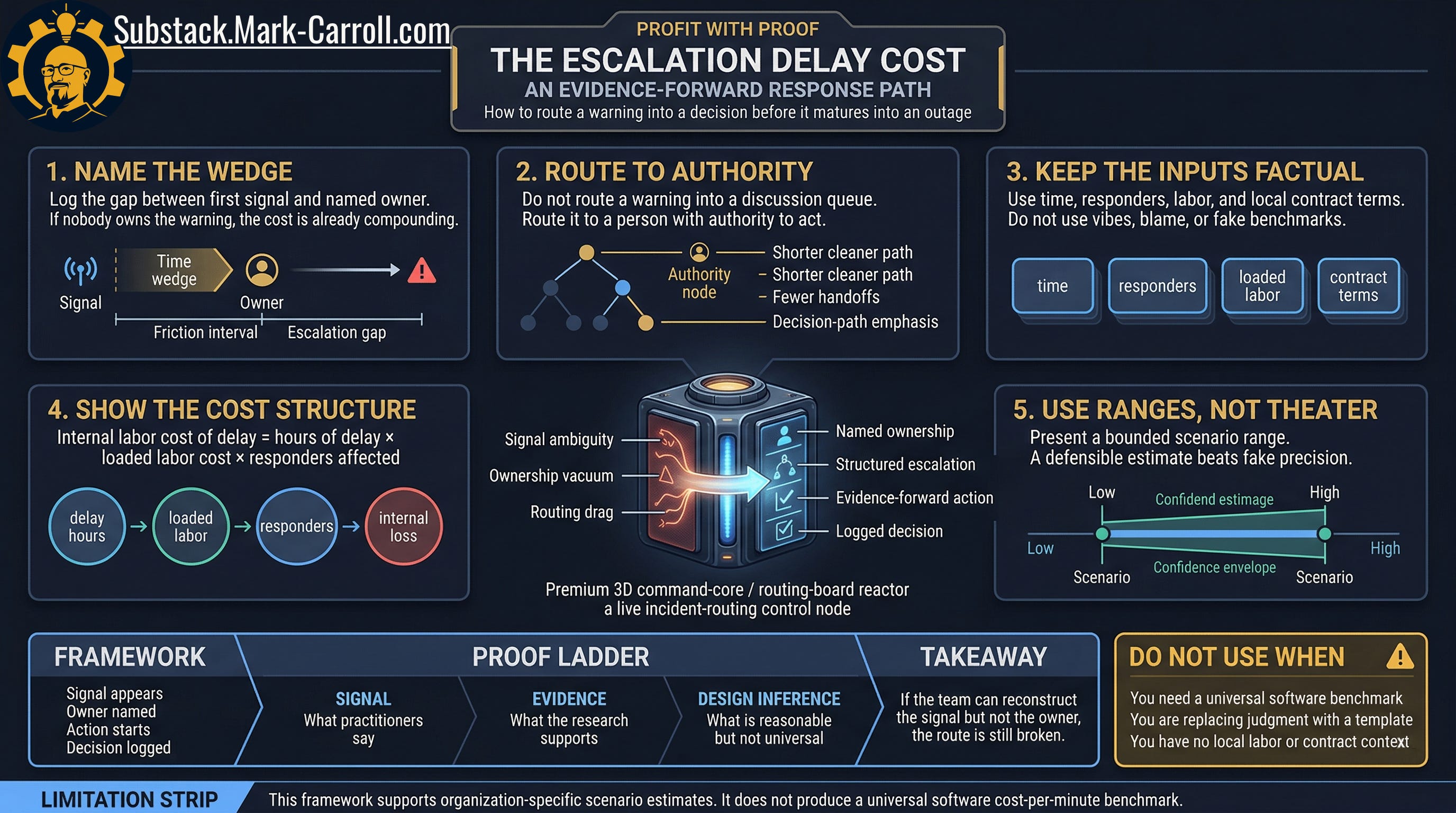
Name the wedge. Log the interval between first meaningful signal and named owner. If the warning exists but nobody owns it, the cost is already moving.
Route to authority. Do not route a warning into a discussion queue or a meeting agenda item. Route it to a person or team with the explicit authority to act.
Keep the inputs factual. Use time. Use responders. Use loaded labor. Use local contract terms where they are real. Do not use blame. Do not use vibes. Do not use generic industry benchmarks that were never derived from your organization.
Make the math visible. Show the cost structure clearly enough that someone senior can challenge it, improve it, and still use it. A number that survives a hard question is worth more than a precise-sounding one that does not.
Use ranges, not theater. A bounded scenario estimate “between $1,400 and $2,600 of internal time, depending on responder count” is far more useful and more defensible than a polished single figure derived from a generic vendor deck.
What leaders should do next
Measure the interval you currently ignore. Not time to meeting. Not time to consensus. Not time until everyone is aware. Time from first credible signal to one accountable person or team with explicit authority over the next action.
Here is a concrete micro-pilot you can run starting with your next five significant incidents:
Record the timestamp of the first credible signal. The moment when a reasonable person could have concluded something needed investigation.
Record the timestamp of the first named owner with authority. Not awareness, not inclusion on a thread, but actual decision authority.
Count the people on the first official response call or channel.
Apply the structural model once: multiply the interval in hours by your loaded labor rate by the responder count. Add any local SLA exposure that is real enough to defend.
Bring one slide with the resulting range to your next incident review. Not a verdict, a range. Ask the room: is this number surprising?
If you do nothing else with this article, start writing down first-signal and first-owner timestamps for a month. The pattern that emerges will tell you more about your organization’s escalation posture than any external benchmark ever could.
Then ask the question most postmortems quietly avoid: how many of your most expensive incidents were really prolonged by uncertainty about ownership, rather than uncertainty about the technical fix?
That question is where the money is hiding.
The closing point
Most teams do not lose time because nobody saw the signal.
Most teams lose time because the signal entered a fog bank of ambiguity. Escalation anxiety. Routing drag. Caution that feels organizationally safer than acting. Performative process compliance that substitutes discussion for decision.
That hidden interval is not free.
It burns labor. It bloats recovery. It compounds customer exposure. It turns recurring lessons into recurring losses. It teaches teams that being technically right matters less than being politically safe. Then it hands the invoice to everyone later.
The escalation delay cost starts at the pause. Not at the outage.
If your team can reconstruct exactly when the signal appeared but cannot quickly name when ownership became explicit, the route is still broken. And if the route is still broken, the next outage is already costing you before it starts.

That idea sits at the heart of the work I am building in my upcoming book, Collaborate Better. Different frame, same underlying truth. When responsibility goes foggy, teams do not just slow down. They get more expensive. You can learn more at CollaborateBetter.us.
And this is only one stop in the larger Profit With Proof series. In the next episode, The Green Dashboard Trap, I will move from internal workflow drag to customer loss, and look at the workflow signals that start flashing before customers leave.


Previous:

More Content to Discover:


Roadmap Keeps Breaking? 3 Fixes for PMs and POs

Top of the Series Arc: 🔒 Leader’s Dispatch: Weight Comes After Insight
Escalation delay is one of those costs most teams feel long before they name it.
If you’ve ever watched a real warning get parked, rerouted, or softened until it became everyone’s problem, this piece is for you.
As I’m sharing this as a Substack Note too, please comment if this captures a pattern you’ve seen in your own org, restack it and tell me where the delay usually shows up: ownership, routing, approvals, or “we’ll monitor it.”