
The $2M AI migration you can't afford (7 traps, 14 contract fixes)
AA-004: The Safety Case File

Top of the Series:

Previous:

The AI Compliance Problem Hiding in Plain Sight
Here’s a question that should make every AI product leader uncomfortable: If a regulator showed up tomorrow asking for proof that your high-risk AI system is compliant, could you actually produce it?
Not a slide deck about your values. Not a principles document. Actual evidence—time-stamped, version-controlled artifacts that prove controls existed before launch and stayed active after.
If you’re hesitating, you’re not alone. And the gap isn’t philosophical—it’s architectural.
The Audit Reality Nobody Talks About
Let me be direct about what compliance actually looks like in practice:
When regulators, external auditors, or enterprise procurement teams examine AI deployments, they don’t want confidence statements. They want a chain of evidence. They want proof that controls existed before launch and proof that controls stayed alive after launch.
If you cannot produce time-stamped, version-controlled artifacts showing how the system was defined, tested, monitored, and attacked, you don’t have compliance. You have a risk story you’re hoping nobody fact-checks.
The key insight here: In high-stakes environments, ambiguity isn’t a neutral state. Ambiguity is a failure mode.
What the Regulations Actually Require
The EU AI Act and NIST AI Risk Management Framework aren’t vague about expectations. They specify concrete documentation and monitoring requirements:
Before market placement:
Technical documentation must be “drawn up before that system is placed on the market” (EU AI Act Article 11(1))
This must include both general descriptions of intended purpose AND detailed technical specs (Annex IV)
The post-market monitoring plan must be part of this pre-market documentation (Article 72(3))
After deployment:
Providers must “actively and systematically collect, document and analyse relevant data on performance” (Article 72(2))
Systems must be “resilient against attempts to alter their use, outputs or performance” (Article 15(4))
Performance must be “measured, assessed, benchmarked, and monitored over the system lifespan” (NIST AI RMF, MEASURE 2.6)
Notice the pattern? It’s not “have good intentions.” It’s “produce specific artifacts at specific times.”
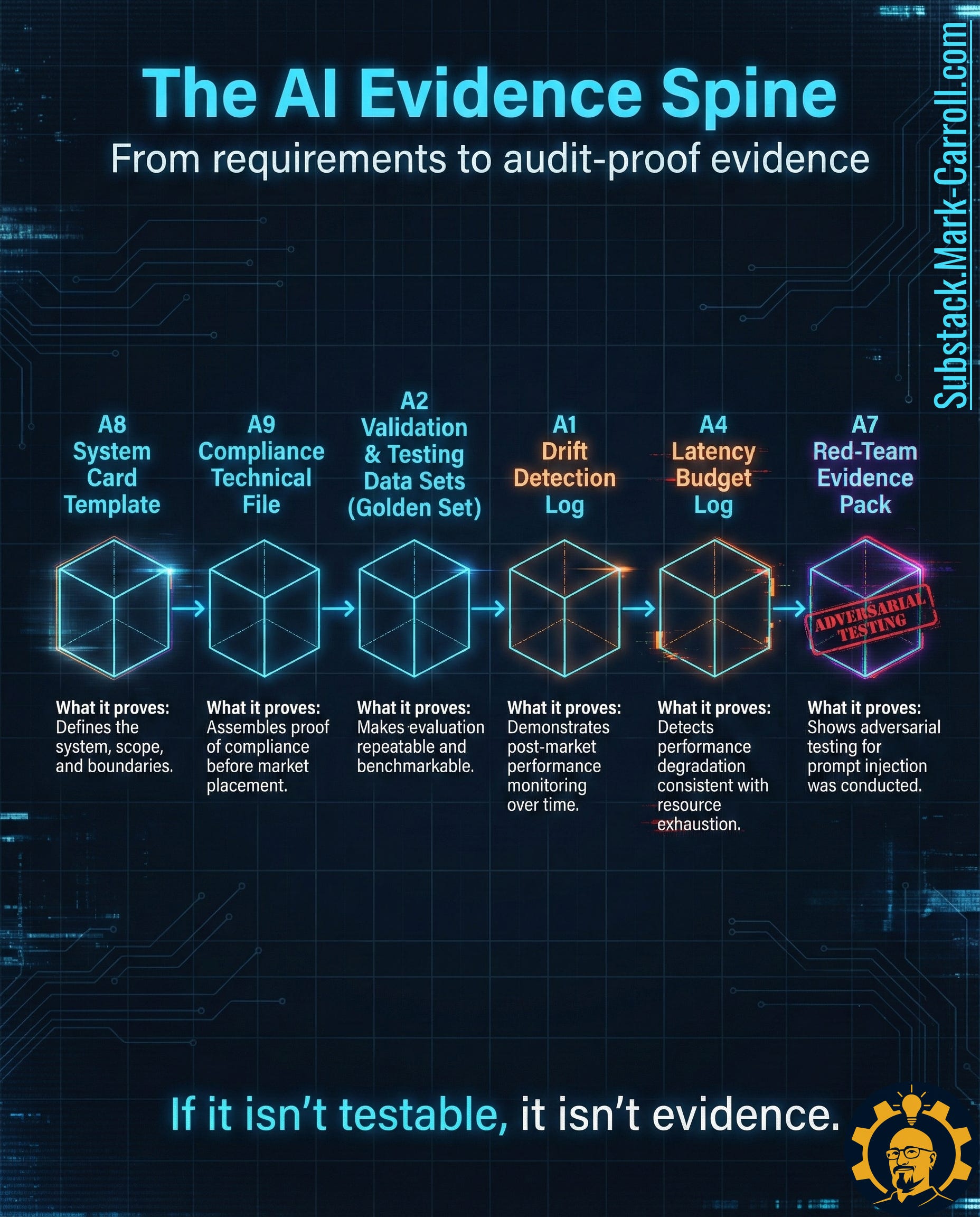
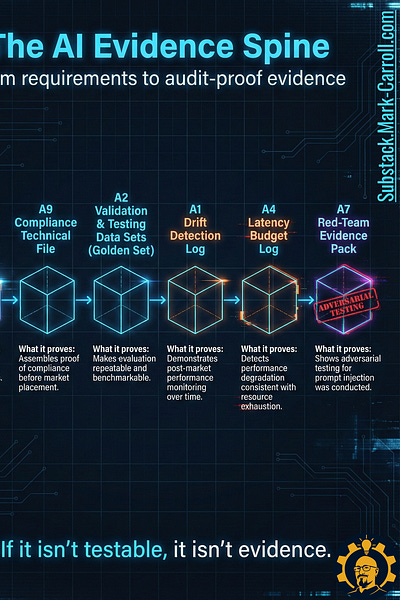
The AI Evidence Spine: Six Artifacts That Turn Regulation Into Proof
Through analysis of these regulatory requirements and security frameworks like OWASP’s LLM Top 10, a clear structure emerges. I’m calling it the AI Evidence Spine—a linear pipeline of six artifacts that moves from definition to testing to monitoring to adversarial validation.
The point is binary. Either the evidence exists, or it does not.
Here’s the spine in deployment order:
A8: System Card Template → Define What You’re Building
What it is: A structured, version-controlled document defining your AI system’s intended purpose, boundaries, inputs, outputs, and human oversight model.
Why it exists in regulation: Annex IV of the EU AI Act explicitly requires:
“A general description of the AI system including: (a) its intended purpose...” (Point 1)
“A detailed description of the elements of the AI system and of the process for its development...” (Point 2)
Why it matters: You cannot govern what you haven’t defined. Without locked scope, your tests aren’t anchored, your monitoring becomes vague, and your risk assessment turns into guesswork.
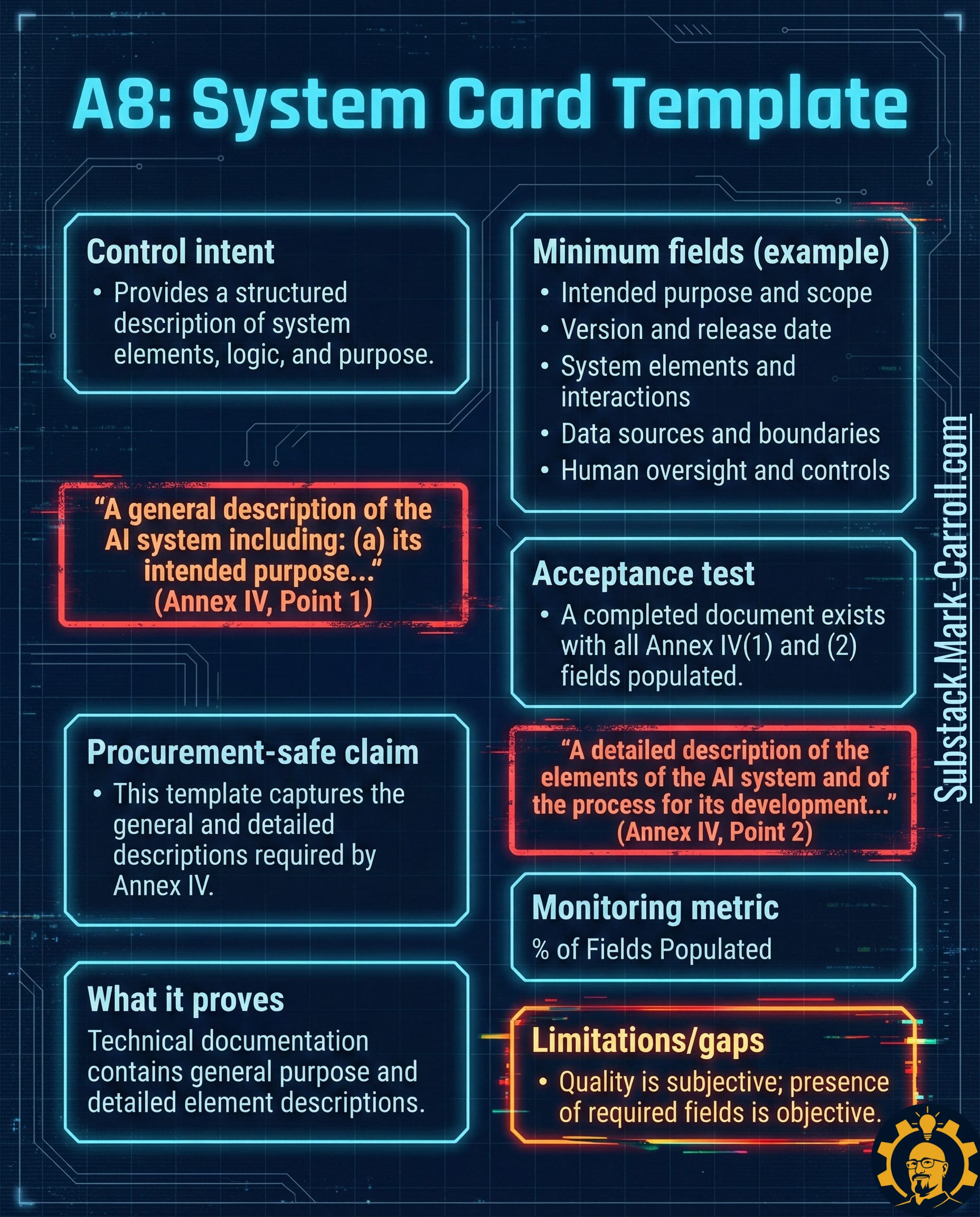
Real-world precedent: Anthropic publishes model cards for Claude. Hugging Face requires model cards for all uploaded models. These aren’t marketing materials—they’re governance primitives that make behavior expectations explicit.
Five tactical steps:
Create a standard template (JSON, YAML, or structured doc) used for every deployment
Require fields that stop ambiguity: intended purpose, excluded uses, model version, system elements and integrations, data sources and boundaries, human oversight model
Store in version control like code—reviews apply, approvals apply
Make it deployment-blocking: no completed System Card = no production release
Schedule quarterly reviews to challenge weak definitions and scope creep
Acceptance test: A completed, version-controlled System Card exists for the current deployment with all required fields populated.
Monitoring metric: Percent of active AI deployments with completed System Card (target: 100%)
Limitation to watch: Presence is objective. Quality isn’t. Someone still needs to read it and challenge vague language.
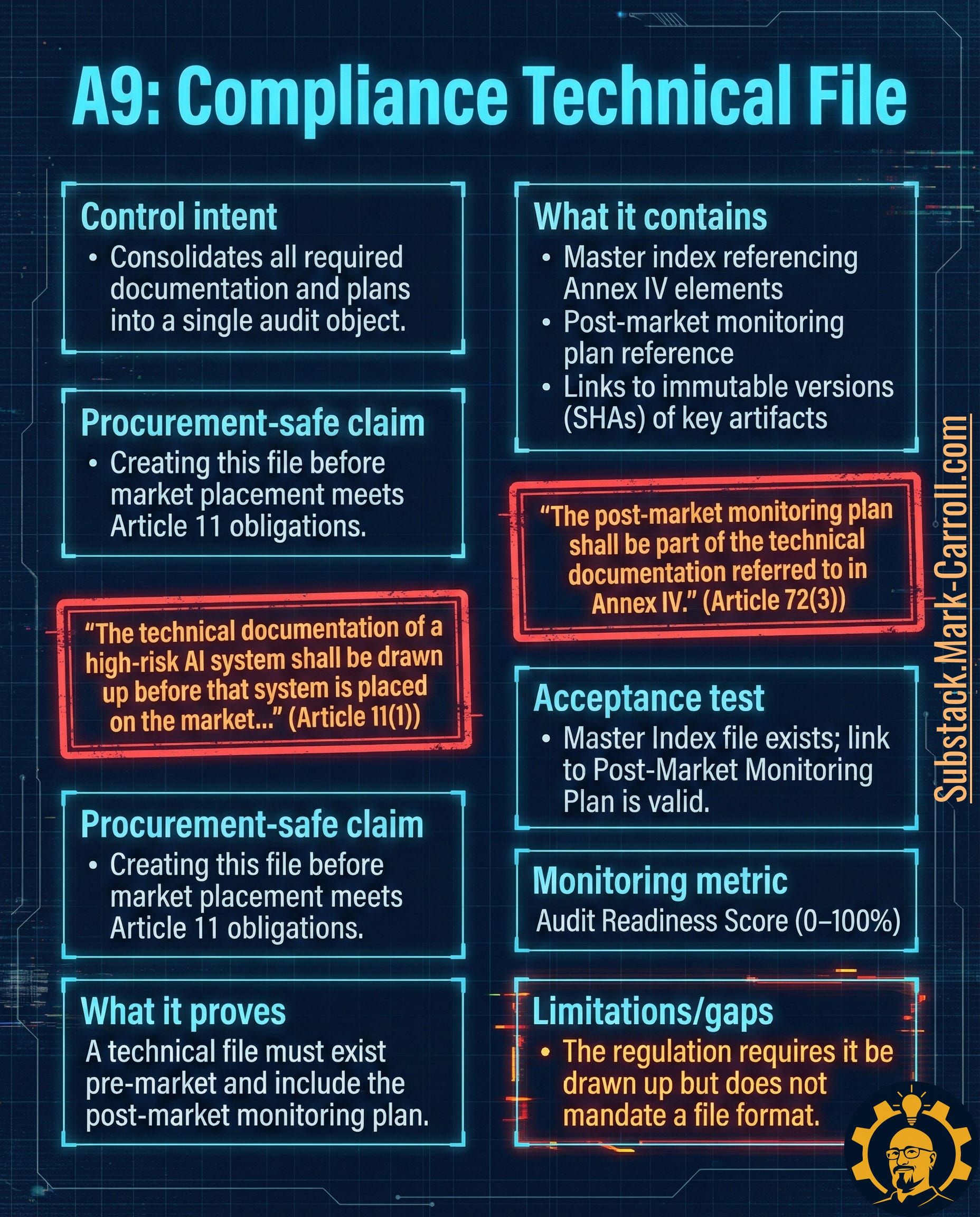
A9: Compliance Technical File → The Master Audit Index
What it is: A structured index pointing to your system description, test evidence, monitoring plan, and post-market documentation. Not a single document—a retrieval system.
Why it exists in regulation:
Article 11(1) requires technical documentation be drawn up before market placement
Article 72(3) requires the post-market monitoring plan be part of it
Timing is explicit: documentation before launch, monitoring plan included
Why it matters: Audits fail in two predictable ways:
Evidence exists but nobody can find it
Evidence exists but nobody can prove it’s tied to the deployed version
The technical file solves both by acting as a single retrieval point with immutable references.
Real-world precedent: Medical device manufacturers have used Design History Files for decades. Same concept, different domain. The format is proven for high-stakes regulatory environments.
Five tactical steps:
Define a standard index format (master markdown file, JSON index, or folder structure with index file)
Include immutable references: git commit SHAs, release tags, dataset hashes pointing to System Card, evaluation reports, monitoring plan
Gate deployments: no technical file = no production release
Automate link validation: broken references = incomplete file
Version the index itself: track what changed and when
Acceptance test: A master index exists containing valid, immutable references to required elements, including the post-market monitoring plan.
Monitoring metric: Audit Readiness Score (0-100% based on index completeness and link validity)
Limitation to watch: The regulation requires the file exist but doesn’t dictate format. Choose one that will still make sense six months later during an audit.
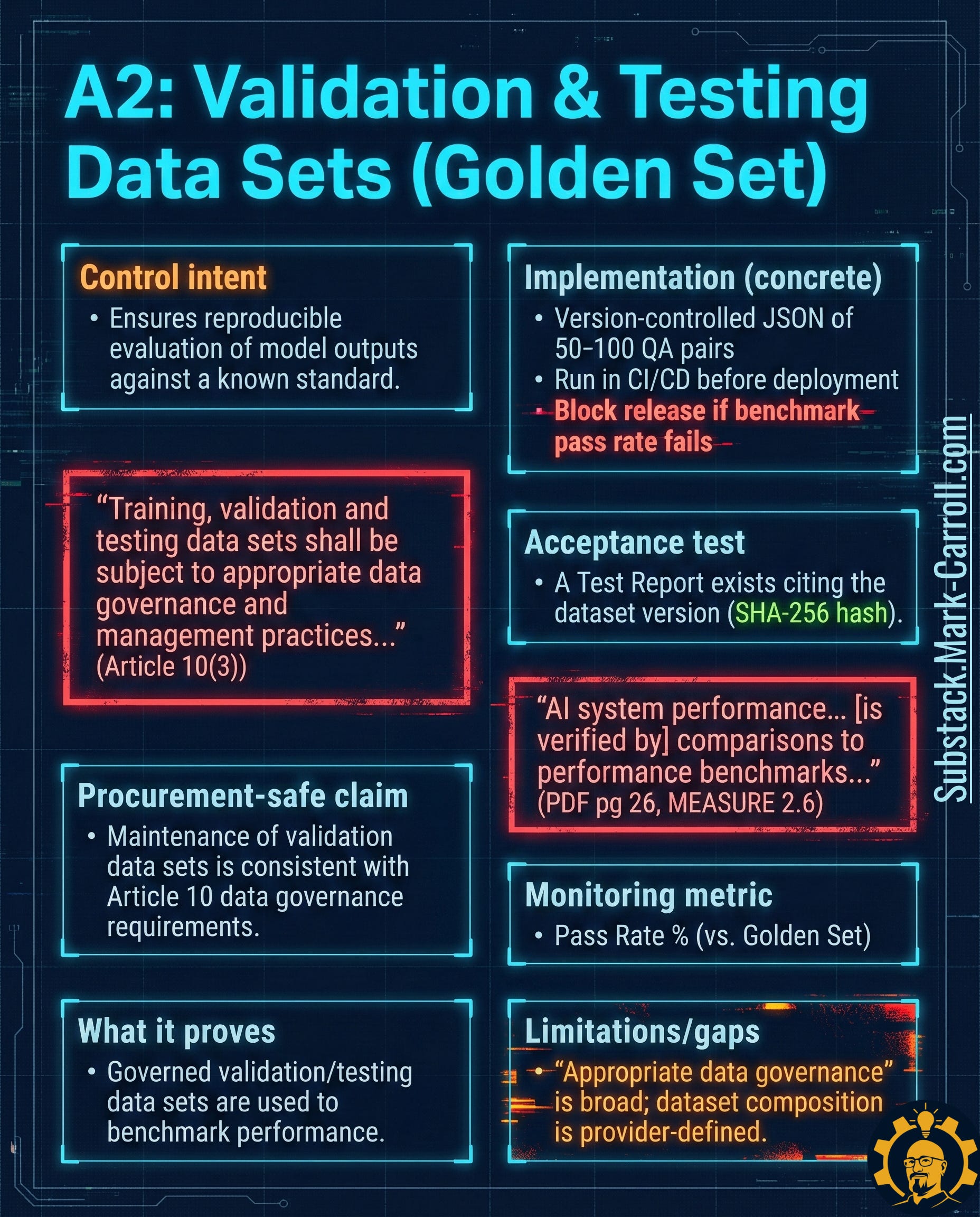
A2: Validation & Testing Data Sets (Golden Set) → Your Repeatable Measurement Instrument
What it is: A governed, version-controlled evaluation dataset used to benchmark performance. Not training data—your standardized test instrument.
Why it exists in regulation:
“Training, validation and testing data sets shall be subject to appropriate data governance and management practices” (EU AI Act Article 10(3))
“AI system performance [is verified by] comparisons to performance benchmarks” (NIST AI RMF MEASURE 2.6)
Why it matters: If you cannot reproduce your evaluation, your evaluation isn’t evidence—it’s an anecdote. A Golden Set turns “we tested it” into “we can prove what we tested and what happened.”
Six tactical steps:
Curate 50-200 high-quality cases representing critical use cases, edge cases, and known failure modes
Store as version-controlled JSON separate from training data
Run automatically for every meaningful change (model update, prompt update, routing change, tool update)
Generate test reports that record the dataset hash and results
Track pass rate trends over time to detect gradual degradation
Schedule quarterly coverage reviews to ensure cases remain relevant
Acceptance test: A test report exists citing the exact Golden Set version (hash) used for evaluation.
Monitoring metric: Pass rate percentage against Golden Set benchmark
Limitation to watch: Golden Sets can bake in blind spots. Governance must include periodic review for coverage gaps, bias, and evolving use cases.
A1: Drift Detection Log → Proof Performance Stays Stable
What it is: Time-series logs of performance stability. You periodically run a fixed prompt set against production and measure how outputs deviate from baseline.
Why it exists in regulation:
“The post-market monitoring system shall actively and systematically collect, document and analyse relevant data on the performance of high-risk AI systems” (EU AI Act Article 72(2))
“AI system performance is measured, assessed, benchmarked, and monitored over the system lifespan” (NIST AI RMF MEASURE 2.6)
Why it matters: AI behavior changes. Sometimes because you changed it. Sometimes because dependencies changed. Sometimes because the world changed. Post-market monitoring isn’t optional for high-risk systems—you need proof you’re collecting and analyzing performance data over time.
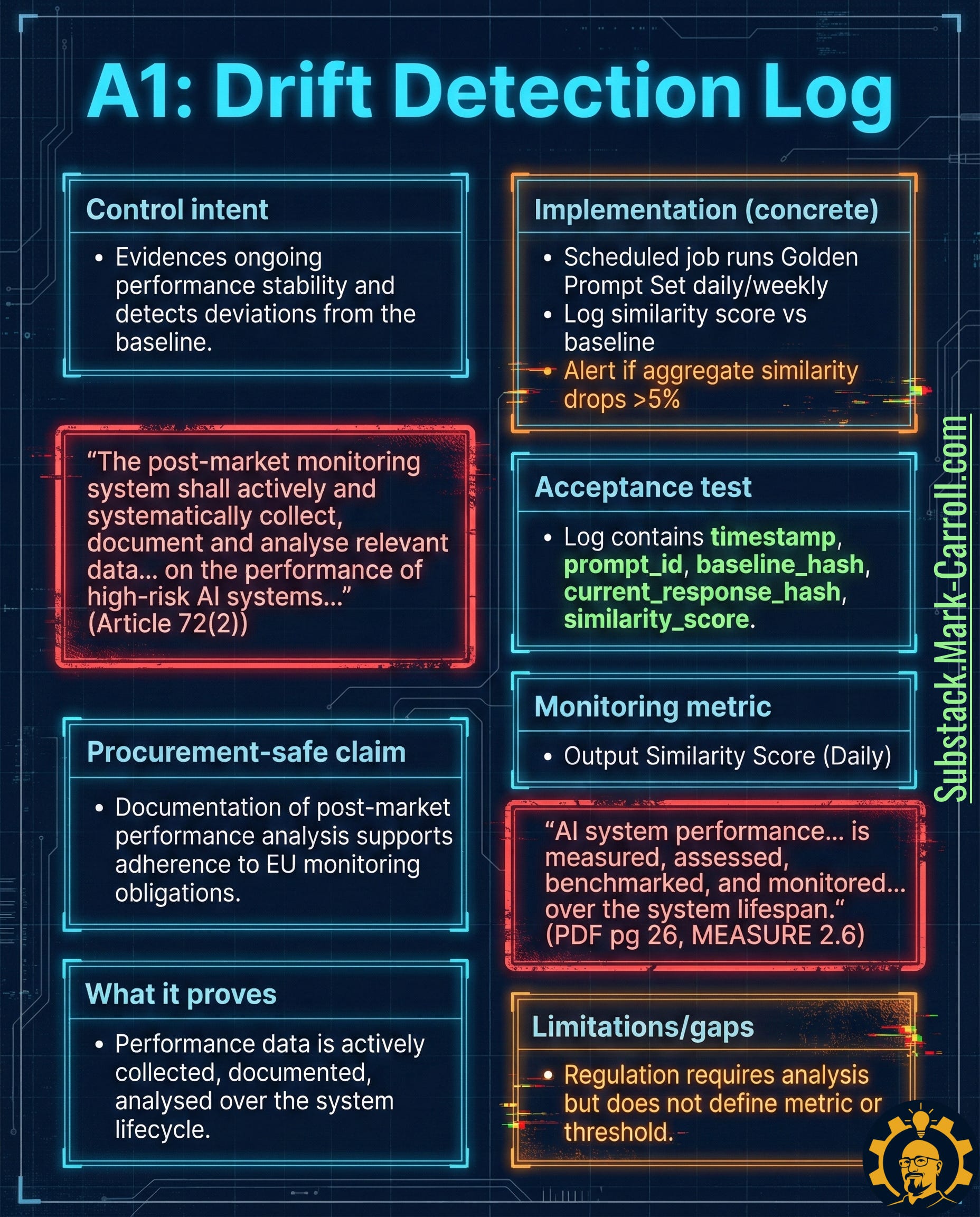
Five tactical steps:
Establish baseline outputs for a fixed prompt set (can overlap with Golden Set if controlled)
Run on schedule: daily for high-risk systems, weekly for moderate-risk
Log required fields: timestamp, prompt_id, baseline_hash, current_response_hash, similarity_score, version identifiers, latency
Alert on meaningful deviations (e.g., aggregate similarity drop >5%)
Document investigation results for flagged deviations
Acceptance test: A structured log exists containing timestamp, prompt_id, baseline_hash, current_response_hash, and similarity_score.
Monitoring metric: Output similarity score (daily or per-run trending)
Limitation to watch: Regulation requires analysis, not a specific drift metric. Your measurement choices must be defensible and tied back to system risk level.
A4: Latency Budget Log → Detect Resource Exhaustion Early
What it is: Logs tracking response time against defined budgets (e.g., P99 latency thresholds), designed to detect resource exhaustion patterns that degrade availability and spike costs.
Why it exists in regulation:
“High-risk AI systems shall be resilient against attempts to alter their use, outputs or performance” (EU AI Act Article 15(4))
“An attacker interacts in a method that consumes an exceptionally high amount of resources” (OWASP LLM04: Model Denial of Service description)
Why it matters: Not all attacks steal data. Some burn compute budgets and destroy uptime. Resource exhaustion is both an attack vector and a reliability risk. Either way, it’s a performance problem requiring early detection.
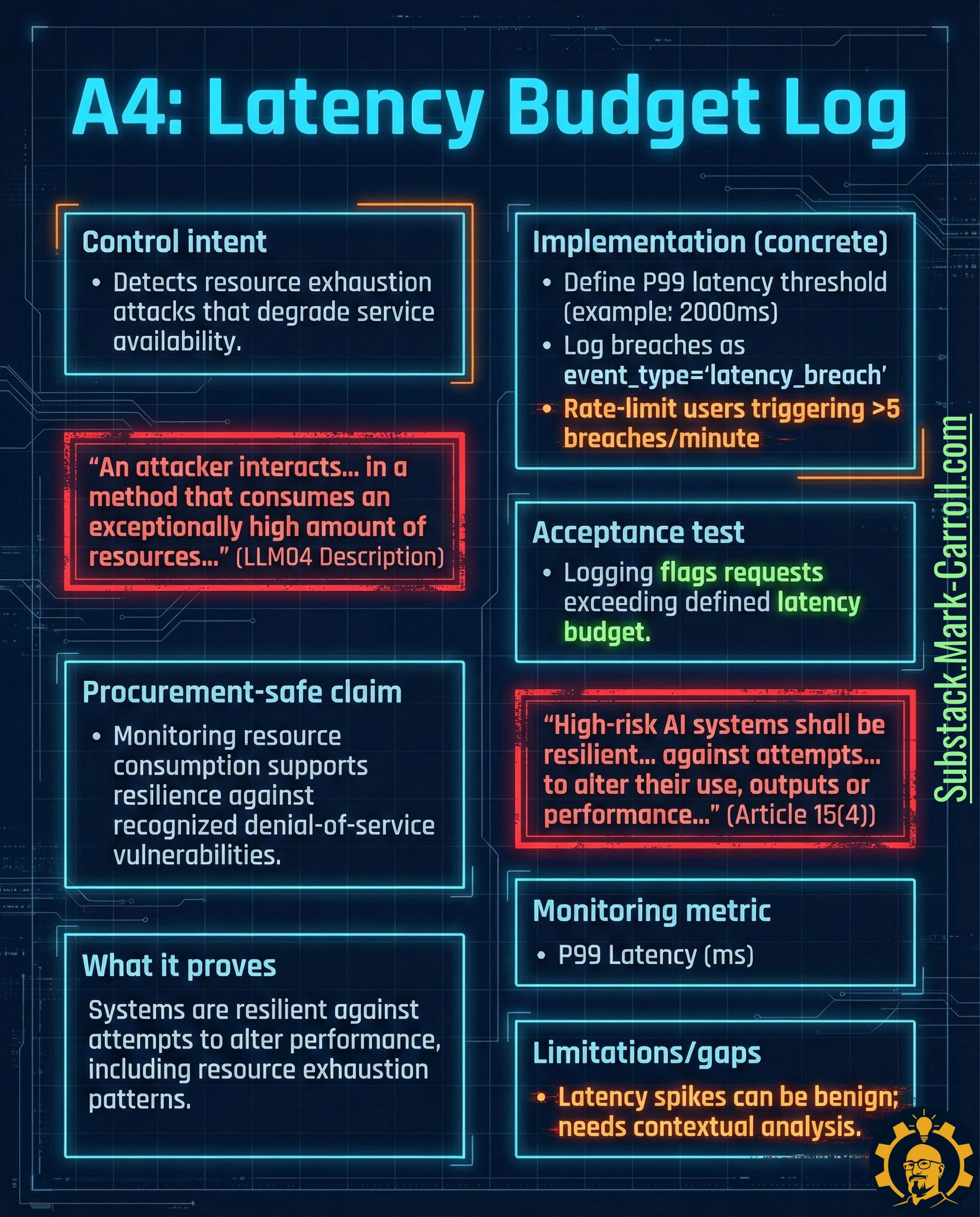
Real-world precedent: OpenAI implements rate limits based on both tokens and compute time. This isn’t just cost control—it’s attack surface reduction.
Five tactical steps:
Define latency budgets by endpoint and prompt type (e.g., P99 <2000ms for standard queries)
Instrument per-request logging: latency, compute cost if available, token counts
Record breaches as dedicated event type (e.g., “latency_breach”)
Implement graduated responses: rate limits, circuit breakers, step-up authentication for repeated breaches
Review breach patterns weekly to distinguish attacks from infrastructure issues
Acceptance test: Logging flags and records requests exceeding the defined latency budget.
Monitoring metric: P99 latency (ms) + count of latency_breach events
Limitation to watch: Latency spikes can be benign (traffic bursts, cold starts). This artifact detects symptoms—investigation determines cause.
If this feels uncomfortably specific, that’s not an accident.
This is the same muscle I’m developing more fully in my upcoming book, Collaborate Better (CollaborateBetter.us): turning abstract risk, culture, and “best practices” into things you can instrument, test, and review without turning leadership into a vibes committee.
Whether it’s people systems or platform systems, the pattern is the same. You don’t prevent failure with trust alone. You prevent it with thresholds, feedback loops, and the discipline to look at what the data is quietly telling you.
And yes, the book goes deeper on how to apply this thinking to teams without making everyone feel surveilled. Because that part matters too.
A7: Red-Team Evidence Pack → Proof You Tried to Break It
What it is: Consolidated evidence package including adversarial testing methodology, raw attack logs, and findings. For LLMs, prompt injection is the headline scenario, but the pack should capture multiple attack vectors.
Why it exists in regulation:
“Prompt injection involves manipulating model responses through specific inputs to alter its behavior” (OWASP LLM01: Prompt Injection definition)
“Red teaming/adversarial testing is conducted to identify vulnerabilities and limitations” (NIST AI RMF GAI-TE.1)
Why it matters: Standard testing checks what the system should do. Red teaming checks what the system can be forced to do. If user input can steer behavior—and with LLMs it absolutely can—then testing must include hostile input.
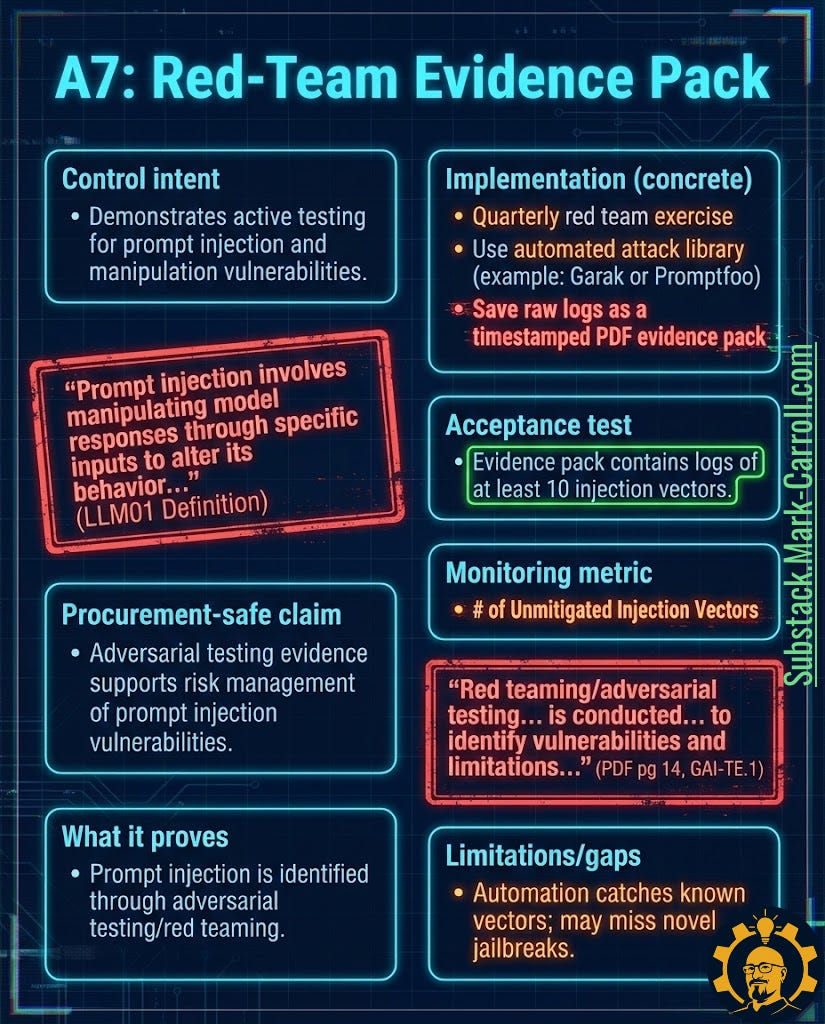
Six tactical steps:
Run quarterly adversarial tests (human-led, automated, or hybrid approach)
Capture raw evidence: prompts, model outputs, tool calls, failure modes
Test multiple vectors: prompt injection, jailbreaks, resource exhaustion, data extraction attempts
Produce timestamped evidence pack (PDF format works fine) including methodology, test cases, outcomes, and remediation actions
Track unmitigated issues in backlog with assigned owners and target dates
Update testing methodology based on emerging attack patterns
Acceptance test: Evidence pack contains logs of at least 10 distinct injection vectors tested against the model, with outcomes recorded.
Monitoring metric: Number of unmitigated injection vectors
Limitation to watch: Automation catches known vectors. Novel jailbreaks will emerge—that’s the point. The pack proves you have a process to keep up.
The 24-Hour Test
Here’s the diagnostic I started using with teams:
If an auditor, board member, or enterprise customer asked you today to prove governance of your AI system, could you produce these six artifacts within 24 hours?
☐ A8: System Card (current version, with approval chain)
☐ A9: Technical File (master index with valid references)
☐ A2: Golden Set test report (with dataset hash)
☐ A1: Drift logs (last 30 days minimum)
☐ A4: Latency breach logs (current period)
☐ A7: Most recent Red Team evidence pack
If you can’t check all six boxes, your compliance posture is aspirational, not operational.
Seven Implementation Priorities
Based on regulatory requirements and documented best practices:
1. Start with A8 and A9 first Definition (System Card) and indexing (Technical File) are foundational. Everything else becomes easier once these exist. They’re also the most frequently requested in procurement reviews.
2. Automate A2 testing in your deployment pipeline Manual testing doesn’t scale and won’t happen consistently. Integrate Golden Set evaluations into CI/CD so every meaningful change triggers evaluation automatically.
3. Make A1 drift monitoring a scheduled job Weekly monitoring is table stakes for high-risk systems. Daily for healthcare and financial applications. This isn’t optional under Article 72(2)—it’s “active and systematic” collection.
4. Instrument A4 latency logging from day one Retrofitting observability is painful and expensive. Start logging before you think you need it. Storage is cheap; missing attack signatures is expensive.
5. Budget for A7 quarterly red teams External red team engagements typically cost $15-30K. If you have security engineering capacity, build internal capability. Either way, make it recurring, not one-time.
6. Store artifacts in version control Git isn’t just for code. System Cards, test configurations, monitoring thresholds, evidence packs—all belong in repositories with complete audit trails.
7. Gate production on artifact completeness Make the Technical File a hard deployment requirement, not a best practice. No complete A9 index = no production release. Build this into your deployment checklist.
The Compliance Stack as Reliability Platform
Here’s what’s interesting: these artifacts don’t just satisfy regulators. They make AI systems more reliable.
Debugging improves because you can trace behavior changes to specific versions and tests.
Reliability improves because drift detection catches degradation early.
Security improves because red teaming finds vulnerabilities pre-production.
Velocity improves because evidence artifacts reduce approval friction in enterprise deals.
Compliance becomes a byproduct of good engineering, not a separate workstream.
Your Evidence Spine Checklist
Use this to audit your current state:
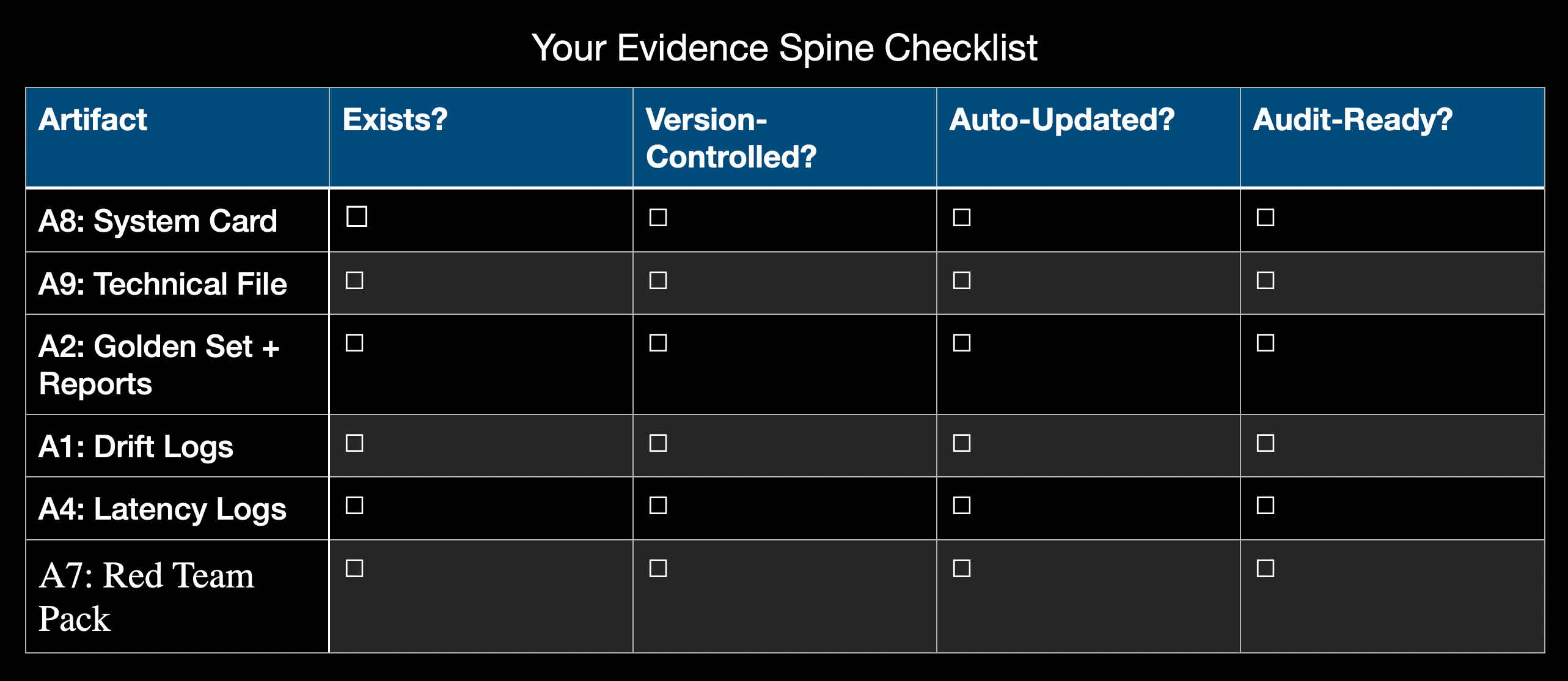
Your weakest link is your first priority. Pick one artifact, build it this month, then move to the next.
Question for Discussion
Which artifact is currently the weakest link in your organization’s AI deployment pipeline, and what’s the first concrete step you can take this month to strengthen it?
The shift from “responsible AI principles” to “auditable AI evidence” is happening whether we’re ready or not. The teams that build the Evidence Spine now will have a significant advantage—both in regulatory compliance and in operational reliability.
The good news? You don’t need to build all six artifacts simultaneously. Start with one. Make it real. Then move to the next.
Based on analysis of EU AI Act requirements (Articles 10, 11, 15, 72; Annex IV), NIST AI Risk Management Framework (MEASURE 2.6, GAI-TE.1), and OWASP LLM Top 10 security standards.
Quick Poll
Which artifact is currently your biggest gap?
System Card (we haven’t formalized scope)
Technical File (evidence exists but isn’t indexed)
Golden Set (we test ad-hoc, not systematically)
Drift monitoring (we don’t track production stability)
Latency tracking (not instrumented as security signal)
Red teaming (we’ve never done adversarial testing)
Drop a comment with your answer—I’m tracking patterns for a follow-up piece on implementation sequencing.
Next:

What Did I Miss?
I’m still learning here. If you’re building AI compliance infrastructure (or wishing you had started sooner), what challenges am I not seeing? What worked? What failed spectacularly?
And if you found this useful, here are three ways to go deeper:
Share with your team — especially if you’re in the “we should probably start documenting this” phase
Subscribe for the follow-up piece on standing up your first Evidence Spine in 30 days
Send me your war stories — I’m collecting case studies for a deeper implementation guide
The shift from “responsible AI principles” to “auditable AI evidence” is happening whether we’re ready or not. Might as well get ready.
Most AI compliance programs are not audit-ready. They are presentation-ready.
If a regulator, auditor, or enterprise buyer gave your team 24 hours to produce proof, which artifact would break first?
System Card
Technical File
Golden Set
Drift monitoring
Latency logs
Red-team evidence pack
Drop your weakest link in the comments. I’m tracking the pattern for a follow-up piece, and I may build the next practical template around the gap that shows up most.